バージョンアップ情報
Apache Kudu情報
Apache Kuduとは
Apache Kudu(アパッチ クドゥ)とは、Hadoopプラットフォーム用に開発されたオープンソースのカラムナ(カラム指向の)ストレージで、2016年9月にバージョン1.0.0がリリースされました。Kuduはアフリカに住むウシ科の動物でロゴマークにもなっています。
カラムナストレージは効率的なデータエンコーディングや圧縮が可能です。単一のカラムのみを読み取ることから検索が高速であり、同じカラムは同一の型データであることから、圧縮も効率的に行えます。したがってカラムナストレージは、ビッグデータを扱うストレージとして適しているといえます。
Apache Kuduは、これまでMapReduceやSparkで使用されていたストレージであるHDFSとHBaseのギャップを補完するために開発されました。
Kuduは、シーケンシャルな読み込みとランダムな読み込み/書き込み双方を同時に行う処理に対して効果を発揮します。たとえば、更新可能なデータを、高速に分析するオンラインレポートのような処理に適しています。
主な特徴
シンプルなデータモデル
Kuduは、リレーショナルデータベースと同様に、テーブルにデータを格納します。テーブルは、Key/Valueストアのような単純なものから、異なる型のカラムが多数存在する複雑なものまで作成することが可能な構造化データモデルです。テーブルは、リレーショナルデータベースと同様に、1つ以上のカラムで構成される主キーを保持します。テーブルの行は、主キーによって効率的に読み込み・更新・削除することができます。
このシンプルなデータモデルにより、アプリケーションの新規開発や既存のアプリケーションを移植することが容易です。
低レイテンシランダムアクセス
Kuduは単なるファイル形式ではなく、テーブルの各行に対してミリセカンドオーダーの低レイテンシアクセスをサポートするライブストレージシステムです。
KuduはOLTPシステムとして設計されているわけではありませんが、メモリに収まるデータのサブセットがある場合、OLTPと同等のランダムアクセスパフォーマンスを提供します。
Apache Hadoopエコシステム連携
Kuduは、Hadoopエコシステムに適合するように設計されており、容易に他のデータ処理フレームワークと連携することが可能です。
Javaクライアントを使用してリアルタイムデータソースからデータをストリーミングし、Spark、Impala、MapReduceなどを使用して即座に処理することができます。 Kuduテーブルに、HDFSやHBaseなどのHadoopストレージに保存されているデータを結合することも可能です。
分散アーキテクチャ
Kuduは、大規模データセットや大規模クラスタに対応し、スケールアウト可能な分散アーキテクチャを持っています。
Kuduは、実データを格納するタブレットサーバとメタデータを扱うマスターサーバで構成され、データは、テーブルに格納されます。テーブルは、パーティションによって分割されたタブレットという連続したセグメントに格納されます。効率的な書込み・スキャンを行うためには、パーティション設計が重要です。パーティションは、レンジ(範囲)とハッシュまたは、双方の組み合わせにより分けることが可能です。
タブレットは、可用性と一貫性を保証するため、レプリケーションに「Raftコンセンサスアルゴリズム」を使用しています。Raftコンセンサスアルゴリズムは、クライアントの要求に応答する前に、少なくとも2つのノードによってすべての書き込みが維持されるようにし、マシンの障害によるデータが損失を防ぎます。
Raftコンセンサスアルゴリズムでは、リーダーとフォロワーというクラスタで構成されています。また、結果整合性(eventually consistency)とは異なり、すべてのレプリカがデータの状態に対して合意する保証と、論理的時刻と物理的時刻の組み合わせを使用することにより、強い整合性を保証することができます。
書き込みはリーダータブレットに対して送信され、タブレットの過半数が書き込みに成功するとクライアントに対して処理の成功を通知します。
図 1 Kuduの書込みフロー
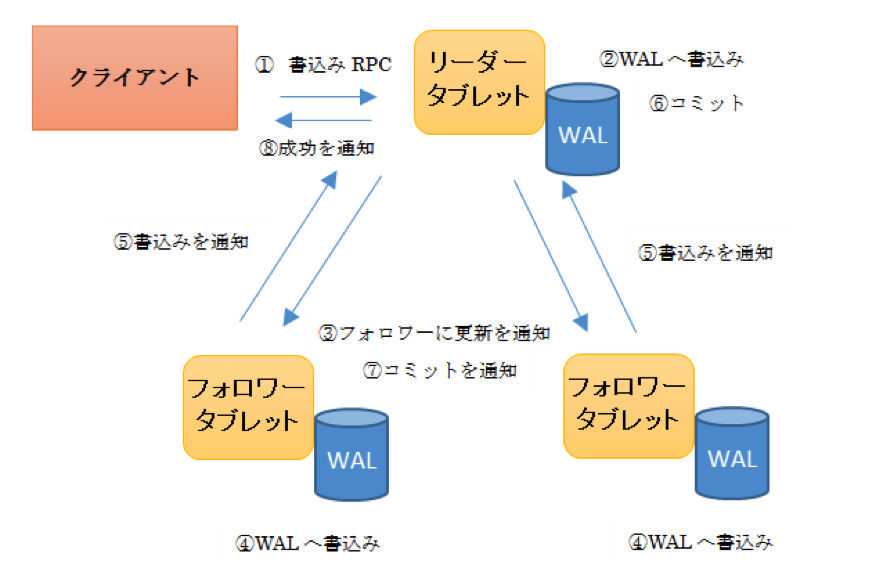
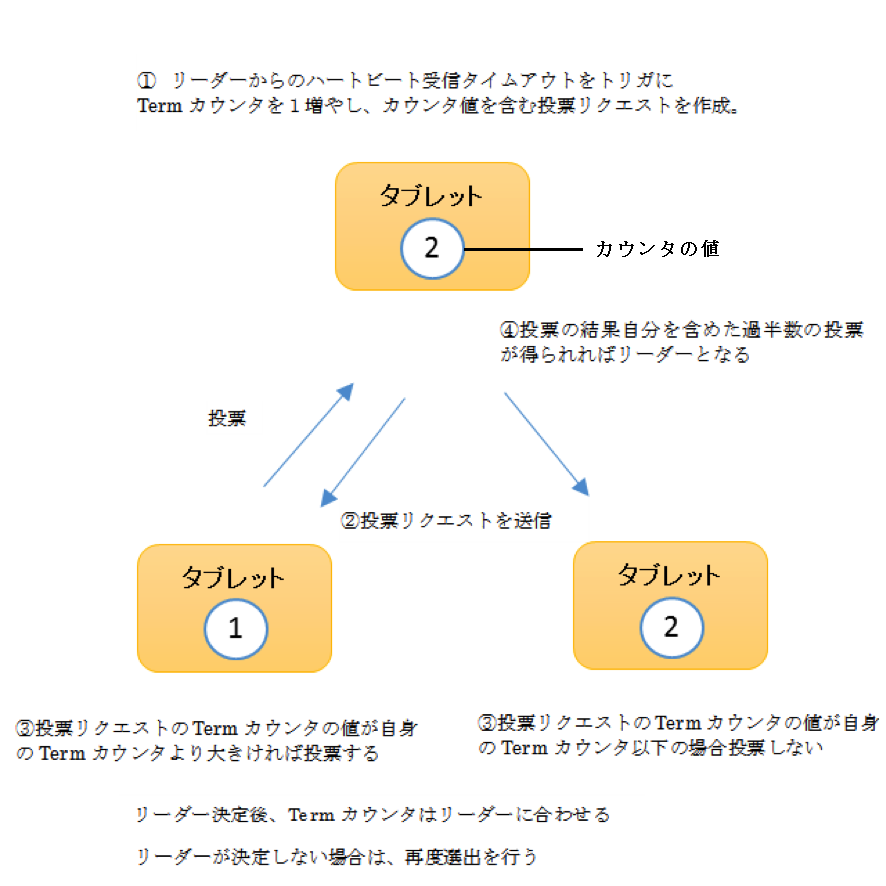
リーダータブレットが停止しても、読み取り専用のフォロワータブレットからデータを読み取ることが可能です。一定期間リーダーからのハートビートの送信がない場合、リーダータブレットの再選出が行われます。
図 2 Kuduのリーダー選出
次世代ハードウェアのための設計
Kuduは、高性能化するハードウェアを先取りするものとして、Cloudera社とIntel社によって共同で開発されました。Intel社の不揮発性メモリプロジェクトで開発された、新しい pmem テクノロジーを利用するよう設計されています。
インメモリカラム指向実行パスにより、KuduはSSE4およびAVX命令セットからのSIMD演算を使用して、インストラクションレベルの並列性を実現できる実装となっています。
※pmem・・・永続的メモリ(persistent memory)のこと。プロセッサのロードとストアの命令を使用して揮発性メモリのようにアクセスできますが、電力損失が起きてもその内容を保持します。
まとめ
Kuduの公式ページによると、代表的なユースケースとして
- 効率的なカラムスキャンによる高速書込み・更新を使用した「リアルタイム解析」
- レンジパーティショニングとハッシュパーティショニングの併用によりデータアクセスのホットスポットを解消した「多様なアクセスパターンを持つ時系列アプリケーション」
- 予測モデルとデータを頻繁に更新し、グラフ化する「予測モデリング」
- Apache Impalaとの連携による「レガシーシステムとの結合」
といったものが挙げられています。それぞれ、Kuduの強みを活かしたデータの書込みと読み込みを並行して行うケースとなっています。
これまでNoSQLの世界では、結果整合性の考え方を採用して一貫性の保証を弱くしたり、トランザクションをひとつのデータアイテムに限るという制限を設けたりすることが多く行われてきました。Kuduも現時点(2023年3月)では、単一行単位でのトランザクションのみ実装されています。しかし、Kuduのドキュメントでは、最終的には完全にACIDとなるよう設計されている、と述べられています。
今後は、一貫性と可用性をより柔軟に調整できるような実装になっていく可能性もあると考えられます。
動作環境
ハードウェア
-
Kuduマスターを実行する1つ以上のホスト
1つのマスター、または3つのマスターを推奨。マスター数は奇数である必要があります。 -
Kuduタブレットサーバを実行する1つ以上のホスト
レプリケーションを使用する場合は、少なくとも3台のタブレットサーバが必要です。
オペレーションシステム
Linux
- RHEL7、RHEL8、CentOS7、CentOS8、Ubuntu 18.04(bionic)、Ubuntu 20.04(focal)
- hole punchingをサポートするカーネルとファイルシステム
- ntpまたはchrony
- xfsまたはext4でフォーマットされたドライブ
- nscdで、DNS 名前解決と静的名前解決のキャッシュをすることを強く推奨
MacOS
- macOS 10.13(High Sierra)、macOS 10.14(Mojave)、macOS 10.15(Catalina)
Windows
- Windowsはサポートされていません。
ストレージ
- Kuduをhighest durabilityに設定し、ソリッドステートストレージが利用可能な高性能なメディアにKudu WALを保存することで、レイテシンが大幅に改善される可能性があります。
Java
- KuduをビルドするためにJDK8が必要ですが、テスト以外の実行時には必要ありません。
Apache Kuduのライセンス
Apache Kuduのライセンスは、Apacheソフトウェア財団 (ASF) によって規定されたApache License Version 2.0を採用しています。
Apache Kuduの使用にあたって、著作権の表示などの条件に従うことで、商用利用、修正、再頒布などが自由に行えます。
製品ダウンロード
参考情報
Apache Kuduのインストールはソースからビルドして行います。詳細はインストール方法のページをご参照ください。
オープンソース年間サポートサービス
OpenStandiaではOSSを安心してご利用いただけるように、オープンソース年間サポートサービスをご提供しております。
サポートしているOSSは下記ページをご参照ください。
関連OSS
-
 サポート対象
サポート対象Apache Spark
アパッチ スパーク。Hadoopの後発として期待されるビッグデータ処理基盤です。
-
 サポート対象
サポート対象MongoDB
モンゴデービー。高可用性、スケーラビリティ、スキーマレスに注目が集まる、NoSQLデータベースです。
-
 サポート対象
サポート対象Apache Hadoop
アパッチ ハドゥープ。Java言語で実装された大規模データの蓄積、分析を分散して処理するフレームワークです。