Apache Solr情報
Apache Solrとは
Apache Solr(ソーラー)とは、Apacheコミュニティによって開発が勧められているオープンソースの全文検索エンジンです。Apache Solrは、SolrのベースとなっているJava全文検索ライブラリであるApache Luceneプロジェクトのサブプロジェクトとして開発されています。
Apache Solrは、インデックス作成と検索のコアにApache Luceneを利用し、JettyやTomcatなどのサーブレットコンテナ内で、スタンドアロンの全文検索サーバとして実行することができます。また、Solrサーバを複数束ねたClusterで構成されるSolrCloudという形態を取ることも出来ます。
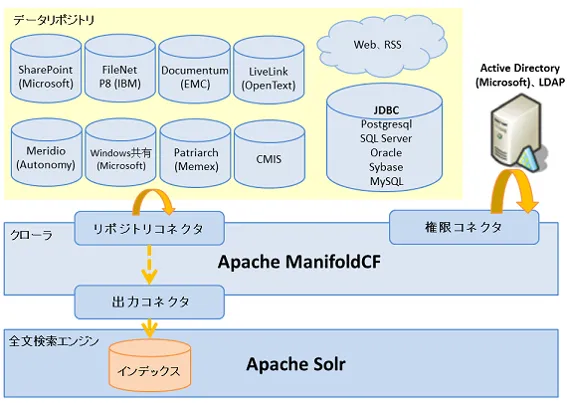
検索対象データの収集には、Apache ManifoldCFなどのクローラと連携することによって、Web上のページ(HTML)やDatabaseに保存されているデータ、CSV、XML、Textなどのファイルと言った、さまざまなソースからデータを読み込み、SolrでIndexを作成することが可能です。
Apache Solrは、強力な全文検索、ハイライト(検索結果の強調表示)、ファセット検索(※1)、ほぼリアルタイムでのインデクシング、動的クラスタリング、リッチテキスト(Word、PDFなど)検索、地理空間的検索、耐障害性機能を備えるなどの特徴があります。
また、HTTP/XMLおよびJSON APIを利用することで、Java以外のさまざまなプラットフォームからSolrの持つ検索機能へのアクセスを可能にしているため、優れた柔軟性と拡張性を備えています。
Apache Solrは、インターネット上のサイト検索システムをはじめ、企業内に蓄えられたファイルや多様なデータを一元的に検索出来るファイル全文検索や知識共有システム、図書館の検索システム、SaaS、SNS、広告配信システムなど、全世界で数多くの導入実績があります。
さらに、Alfresco(ECM)、Liferay(EIP)、Drupal(CMS)といった、多くのオープンソースソフトウェアにおいて全文検索エンジンとしてSolrが組み込まれています。
- ファセット検索:あらかじめサイト側が用意した商品分類や金額帯などの検索候補条件を選択し、コンテンツの絞り込みをする検索ナビゲーションの仕組み。
主な機能
主な機能は以下のとおりです。
|
検索/ソート機能 |
クエリ検索、インデックス、ファセット、ハイライト(検索結果の強調表示)、スコアリング、範囲検索、緯度経度検索、類似文書検索、グルーピング、リッチテキスト検索、カスタムランキングなど |
|---|---|
|
分散機能 |
インデックスレプリケーション、分散横断検索、分散検索(SolrCloud) |
|
レプリケーション機能 |
クラスタリング、シャーディング、自動インデックスレプリケーション、自動フェイルオーバー |
|
データインポート機能 |
Apache TikaとDataImportHandler(DIH)の利用により、Microsoft オフィスファイル、PDFファイル等をインポート |
|
管理インタフェース |
各種設定の実施、キャッシュ使用率やクエリ、クラスタノードステータスといったサーバの各種統計情報を監視するための管理画面 |
|
その他 |
スペルチェック、レコメンド、スコアブースト、トークナイザ(形態素解析)、トークンフィルタなど |
主な特徴
主な特徴は以下のとおりです。
|
高機能な全文検索エンジン |
クエリ検索、インデックス、ファセット、ハイライト(検索結果の強調表示)、スコアリング、範囲検索、緯度経度検索、類似文書検索、グルーピング、リッチテキスト検索、カスタムランキングなど、さまざまな方法での全文検索が可能 |
|---|---|
|
Javaベース |
Javaベースのアーキテクチャのため、同じくJavaベースで構築されていることが多い企業情報システムとの親和性が高く、比較的容易に他システムとの連携が行える |
|
高速 |
分散インデックス検索、クエリーキャッシュ機能など、大量のWebトラフィック用に最適化されている |
|
高い拡張性 |
Solrサーバのクラスタをより容易に構築し管理するためのツールが提供され、スケールアウトしやすい |
|
マルチOS/マルチクライアント |
さまざまなサーバOSおよびクライアント環境に対応 |
|
オープンスタンダードなインタフェース |
XML、JSONおよびHTTPを利用してさまざまなプラットフォームから検索機能へのアクセスを実現し、柔軟性と拡張性に優れたXMLでの設定が可能、バージョン8からはHTTP/2もサポートされた |
|
包括的なHTML管理インタフェース |
各種設定の実施、インデックス統計、キャッシュ使用率、クエリ、テキスト分析デバッガ、クラスタノードステータス、SolrCloudダッシュボードといったサーバの各種統計情報を監視するためのAJAXベース管理画面を備える |
|
耐障害性 |
自動インデックスレプリケーション、自動フェイルオーバーおよびリカバリ機能を備え、単一障害点がない |
|
導入しやすい |
オープンソースでライセンス費用がかからないうえ、いくつかの簡単なコマンドですぐに検索エンジンを利用できる |
|
運用しやすい |
カスタマイズ可能な検索パラメータが豊富であるほか、管理画面や耐障害性機能を備え、スケールアウトを考慮した機能も充実 |
|
多言語対応 |
トークナイザと言語フィルタが充実しており、数十か国もの言語をサポートしているほか、日本語検索の単語抽出方法に「形態素解析」と「N-gram」を選択でき、柔軟な対応が可能 |
|
豊富な導入実績 |
検索プラットフォームとして、国内外を問わず多数の採用実績がある |
|
コスト効果 |
特別なハードウェアを必要とせず、ライセンス費用もかからないため、商用製品に比べて大幅に導入コストを削減可能 |
導入事例
Apache Solrは、オープンソースの全文検索エンジンとして、中小から大規模まで、さまざまな業種で幅広く利用されています。
Apache SolrのWikiページでは、下記の企業や団体のWebサイトをApache Solr導入事例として掲載しています。
上記の他にも、Apache Solr導入事例がApache Solrコミュニティサイトに数多く掲載されています。
Apache Solrは、インターネットのサイト検索システムをはじめ、企業内でのファイルサーバや多様なデータの検索や知識共有システム、図書館の検索システム、SaaS、SNS、広告配信システム、政府系機関システムなどに数多く採用されています。
類似プロダクト
-
商用ソフトウェア製品
Sedue、FAST ESP、CBES(ConceptBase Enterprise Search) -
OSS製品
Apache Lucene、Elasticsearch、Katta、Senna、Namazu
動作環境
前提となる動作環境は、以下のとおりです。(バージョン8.6の場合)
-
OS
- ・Linux/MacOS/Windows
-
Java Runtime Environment(JRE)1.8以上
- ※Oracle JDKもしくは、OpenJDK が最もよく検証されている JREであり、このどちらかが推奨されます。
- ※Java VMのいつくかのバージョンでは、動作に影響があるバグがあります。Lucene JavaBugsのページを確認ください。
※バージョンによって異なりますので、詳細はお問い合わせください。
Apache Solrのライセンス
Apache Solrのライセンスは、Apacheソフトウェア財団 (ASF) によって規定されたApache License Version 2.0となっており、ユーザは、Apache Solrの使用にあたって、著作権の表示などの条件に従うことで、 使用や頒布、修正、派生版の頒布をすることに制限を受けません。
製品ダウンロード
オープンソース年間サポートサービス
OpenStandiaではOSSを安心してご利用いただけるように、オープンソース年間サポートサービスをご提供しております。
サポートしているOSSは下記ページをご参照ください。