バージョンアップ情報
Apache Kafka情報
Apache Kafkaとは
Apache Kafka(アパッチ カフカ:以下Kafka)は大量のイベントデータをリアルタイムに収集し、連携先のサービスが必要に応じて自らデータを取得できる仕組みを提供します。
データを一元的に管理し、各サービスが自律的に取り出せるデータの集積基盤としての役割を果たします。
公式サイトでは、Kafkaは「分散イベントストリーミングプラットフォーム」と説明しています。
「分散」とは複数のサーバで1つのクラスタを構成し、各サーバ上にデータを分散配置・処理するスケールアウト可能な仕組みです。
これにより高いスケーラビリティと耐障害性を実現しています。
「イベントストリーミング」とは、従来型のバッチ処理のようにイベントデータを一定量蓄積してから処理する方式と異なり、「商品が売れた」「センサーが温度を検知した」「サーバのログが発生した」といったイベント発生の都度、データを継続的に取り込み、順次利用できる状態にする処理方式です。
従来のメッセージキュー(Message Queue: MQ)が対象とする単なるリアルタイムなデータ受け渡しにとどまらず、イベントデータの長期保存と再利用や複数サービスが同時にデータを取得・活用できる点が大きな特徴です。
従来のシステムでは全体を貫く統一的なデータ連携基盤がないため、送受信を行うサーバ間ごとにデータ連携方式を設計・実装することが少なくありませんでした。
これに対しKafkaは「情報の交差点(ハブ)」として機能するため、データ連携方式を個別に設計・実装する必要がなくなり、スムーズで柔軟なデータ連携が可能になります。
Kafka本体 (サーバ機能)はJavaとScalaで実装されたオープンソースソフトウェアです。
クライアントについては各種プログラミング言語向けライブラリを提供しており、JavaやScalaだけでなく、PythonやC/C++などでも開発が可能です。
開発の背景と歴史
KafkaはビジネスSNSサービスを提供するアメリカのLinkedInで2011年頃に開発されました。
当時、LinkedInはデータ量の急増に伴い、深刻な課題に直面していました。
ユーザの行動ログやシステム監視ログといった様々なデータを各サービスに連携しようとした結果、サービス同士が複雑に絡まり合う構成になっていました。
またデータ連携のたびにサービス間で直接接続したり、メッセージングキューを介したりする従来の方式では1日あたり数千億件にものぼる膨大なデータを遅延なく、かつ大量に処理することが困難で、処理方式自体の見直しが必要となりました。
LinkedInのエンジニアたちはこれらの課題を解決するために「すべてのデータを一箇所に集め、整理された順序で記録する『巨大なログシステム』」としてKafkaを開発しました。
その後、KafkaはApacheソフトウェア財団のプロジェクトとして認められ、同財団の管理下でオープンソースソフトウェアとして開発が続けられています。
さらにLinkedInでKafkaの開発に関わった主要メンバーはConfluentという会社を立ち上げ、Kafkaのエンタープライズ向けサービスを展開しています。
主な特徴
Kafkaは複数のアプリケーションやデータベース間でイベントデータの中継点として機能します。
高い信頼性を保つため、受け取ったデータを即座に複数のサーバへ複製(レプリケーション)し、一部のサーバが故障してもデータを失わず処理を継続できるフォールトトレラント(耐障害性)な設計となっています。
Kafkaの全体アーキテクチャ
Kafkaの全体アーキテクチャを以下に示します。
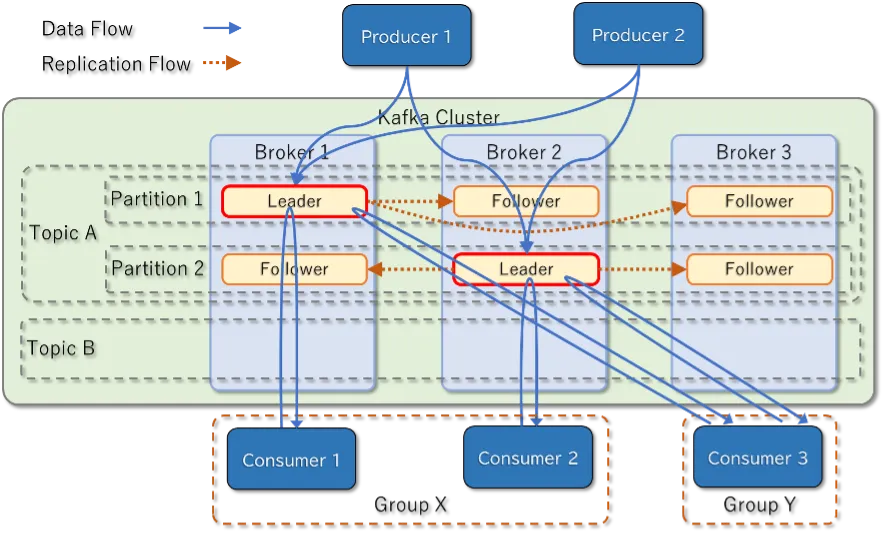
Kafkaは以下の3つのコンポーネントから構成されます。
- Producer
- Apache Kafka Cluster(以下、Cluster)
- Consumer
ProducerはClusterに対してデータを送信します。
この送信データの最小単位をRecordと呼びます。
ClusterはBrokerと呼ばれる複数のノードの集合で、Producerから受信したデータを管理・蓄積します。
Clusterにはデータの論理的な格納先となるTopicが存在し、これはリレーショナルデータベースにおけるテーブルに相当します。
1つのCluster内には複数のTopicが存在することができます。
TopicはPartitionと呼ばれる複数の区画に分けられており、RecordはいずれかのPartitionに格納されます。
PartitionはBroker間にまたがって存在し、Recordを冗長化して保管しています。
Partitionのデータ構造は連続的な追加処理に特化しており、更新(上書き)を想定していません。
Recordはkey-valueを中心とした形式で構成されており、キーに基づいて特定のPartitionへ割り振られます。
同一キーのRecordは常に同じPartitionへ送られるため、Partition内での時系列順序(到着順)が保証されます。
ただし、異なるPartitionに分散されたRecord同士での順序は保証されません。
キーが指定されていない場合はラウンドロビンなどの方式で各Partitionへ均等に振り分けられます。
このようにTopicをPartitionに分割し、データを複数のBrokerに分散配置することで並列処理が可能となります。
この仕組みがKafkaの高いスケーラビリティを支えています。
ConsumerはTopicに蓄積されたデータを取得します。
Kafkaではサーバ側からデータを一方的に送り付けるのではなく、Consumer(受信側)がデータを読み取る「プル (Pull) 型」のモデルを採用しています。
これにより受信側が自らの処理能力に合わせてデータを処理することができます。
Consumerを複数用意することでデータ取得の並列化が可能です。
上図の例のようにGroup X, Group Yという2つのConsumerグループがある場合、各グループには以下のようにConsumerが属しています。
- Group X
- Consumer 1
- Consumer 2
- Group Y
- Consumer 3
Group XではTopic Aのデータを以下のように分担して読み取ります。
- Partition 1 → Consumer 1
- Partition 2 → Consumer 2
このようにConsumerを増やすことで処理能力を向上させることができます。
ただし、Partition数を超えた並列化はできません。
またConsumerグループに耐障害性を持たせることができます。
この例ではConsumer 2に障害が発生した際にConsumer 1がPartition 2も読み取るようにすることができます。
次にGroup XとGroup Yは同じデータをそれぞれ独立して取得することができます。
例えば、
- Group Xは「リアルタイム分析用」
- Group Yは「長期ログ保存用」
といった具合に同じTopicから異なる目的でデータを活用できます。
これは従来のメッセージキューにないKafkaの強みの一つです。
Kafkaではデータの保持期間を柔軟に設定できます。
保持期間を短く設定して古いデータを自動的に破棄すればストレージ使用量を一定に保ち、パフォーマンスを安定させることができます。
一方、保持期間を長く設定すれば過去のデータを長期間保持し、後から再利用することも可能です。
KafkaのコアAPI
Kafkaには5つのコアAPIが存在します。
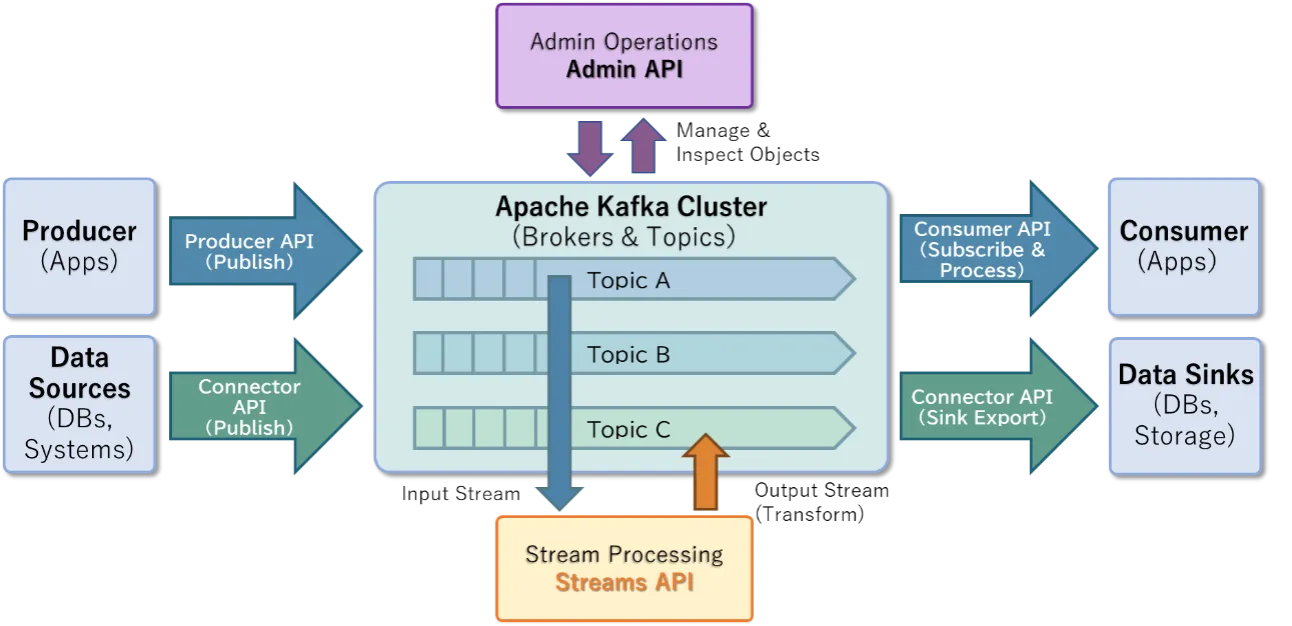
- Producer API
アプリケーションからBroker向けにイベントデータを送信する機能を提供するためのAPIです。
送信元はアプリケーションだけでなく、データベース連携ツールなども含まれます。
- Consumer API
アプリケーションがKafkaのTopicを購読し、Recordを読み取って処理するためのAPIです。
Consumerは自分の必要に応じてデータを読み進める「プル型」の方式で動作します。
- Streams API
KafkaのTopicを入力として継続的に読み込み、変換・集計・フィルタリング・結合などのストリーム処理を行い、結果を別のTopicへ出力するアプリケーションを実装するためのAPIです。
これにより、外部の処理基盤を別途用意せずに、アプリケーション内へストリーム処理ロジックを組み込めます。
- Connect API
Kafkaと外部システム(データベース、ストレージ、SaaSなど)を接続し、データの取り込み(Source)や書き出し(Sink)を行うための仕組みです。
外部システムからKafkaへデータを取り込むSourceコネクタと、Kafkaから外部システムへ書き出すSinkコネクタを利用し、アプリケーションを個別に開発しなくても、設定を中心に継続的なデータ連携(インポート/エクスポート)を構築できます。
- Admin API
Topicの作成・設定変更、Brokerやクラスタ状態の確認など、Kafkaの各種オブジェクトを管理・運用するためのAPIです。
ユースケース
Messagingシステム
Kafkaは高いスループット、Partitionによる並列処理、レプリケーションによる耐障害性を備えているため、大規模なメッセージング基盤として利用できます。
従来のメッセージブローカー(ActiveMQやRabbitMQなど)との大きな違いは、Kafkaが「分散ログ」を基盤としている点です。
メッセージは消費された後も一定期間保持されるため、複数のシステムで同時にデータを利用したり、障害発生時に過去のデータから再処理を行ったりすることが容易です。
Webサイトのアクティビティトラッキング
Kafkaは元々、LinkedInにおいてWebサイトのユーザ行動データを収集・活用する基盤として開発されました。
Webサイトやアプリ上のページビュー、検索、クリックなどのユーザ行動を継続的に収集し、その後段の分析基盤(HadoopやElasticsearchなど)が取得して処理します。
これにより、リアルタイムなユーザ動向の把握や施策の効果測定に活用できます。
メトリクスやログの収集
サーバやアプリケーションから出力されるメトリクス(CPU使用率、メモリ使用量など)や、分散したシステムに点在するログファイルから抽出されたデータをKafkaに集約します。
監視システム(Prometheus、Grafanaなど)やログ分析基盤(Elasticsearch、Splunk、OpenSearchなど)は、Kafkaから必要なデータを取得することで、リアルタイム監視やトラブルシューティングを効率的に行えます。
この分野にはFlumeなどの類似のソフトウェアが存在します(なお、Flumeは現在メンテナンスが停止しています)。
ストリーム処理
Kafka上のデータストリームをストリーム処理エンジンでリアルタイム処理します。
Kafka自体はログを保持し、外部エンジンに処理を任せることもできます。
この分野にはApache StormやApache Samzaが類似のソフトウェアとして存在します。
リアルタイム分析
リアルタイム分析とは発生したデータを即時に処理し、現在の状況を可視化することに特化した活用方法です。
Webのアクティビティに限らず、金融取引データのストリームから不正利用を即座に検知したり、工場内のIoTセンサーデータから機器の故障予兆をアラート発報したりするなど、「今、何が起きているか」を把握するために利用されます。
Kafkaとストリーム処理エンジンや可視化ツールを組み合わせることでタイムラグの少ないモニタリングが可能になります。
可視化・分析基盤となるソフトウェアとしては、ElasticsearchやApache Druidが存在します。
イベントソーシング
イベントソーシングとはアプリケーションの「現在の状態(結果)」だけを保存するのではなく、状態を変化させた「すべてのイベント」を時系列のログとして記録し続ける設計手法のことです。
Kafkaはイベントを不変のログとして順番通りに保存し、履歴を再読み込みすることで任意のタイミングの状態を再現できる特性から、イベントソーシングの理想的な基盤として活用されています。
一方で、イベントログはそのままでは複雑な検索や集計には毎回すべての履歴を再計算する必要があり非効率です。
そこでデータの更新と参照の処理を切り離すCQRS(Command Query Responsibility Segregation)設計を組み合わせます。
データの更新(コマンド)はKafkaへの記録に専念させ、データの参照(クエリ)はKafkaから取得したイベントを検索に適した「読み取り専用データベース」へ反映して行います。
この構成により、「履歴の完全な保存」と「高速なデータ検索」の両立が可能になります。
マイクロサービス間通信
Kafkaを「メッセージブローカー(中継役)」として利用します。
各サービスはイベントを発行し、他サービスは必要なタイミングで購読します。
これにより各サービスが互いの完了を待たずに非同期にデータのやり取りができるので、特定のサービスで発生した遅延がシステム全体に波及しにくくなります。
適用例として、注文が入った瞬間に「注文サービス」がKafkaに通知し、それをトリガーに「キッチン向け通知」「配達員マッチング」「決済」の各サービスが同時に動き出すデリバリー配送アプリでの利用があります。
RabbitMQやApache Pulsarが類似のソフトウェアとして存在します。
データ基盤連携
Kafka Connect(Connect API)により、既存データベースや外部システムと連携できます。
収集したデータは解析のためにHadoopなどの大規模システムが取得できます。
用途が一部重なるソフトウェアとして、ログ収集基盤であるFluentdが挙げられます。
コミットログ
Kafkaは分散システムの外部コミットログとして機能します。
ノード間のデータ複製や障害時のデータ復元のメカニズムとしても機能し、Topicを用いて書き込み/読み出しを並列に行うことで、高速かつフォールトトレランスに優れた通信を実現します。
動作環境
Kafkaは下記に示すUnix系OS上で動作します。
Windowsで稼働させるにはまだいくつかの問題が残っているため、現状ではWindowsは十分にサポートされるプラットフォームには含まれていません。
- 主要なLinuxディストリビューション
- Solaris
- macOS
稼働させるにはJVM(Java仮想マシン)が必要になります。
Kafkaの動作には分散クラスタのメタデータ管理 (同期・設定情報管理) の仕組みが必要で、以前はApache ZooKeeperがその役割を担っていました。
しかし、Kafka2.8で独自の仕組みであるKRaft(Kafka Raft)モード が試験的に導入され、段階的な移行期間を経て、Kafka4.0でApache ZooKeeper モードが削除されました。
Apache ZooKeeperへの依存が解消されたことで、Kafkaはよりシンプルで、かつ強力なシステムへと進化しました。
Apache Kafkaのライセンス
KafkaはApacheのトップレベルプロジェクトの1つです。
ライセンスはApache License 2.0となっており、ユーザはそのソフトウェアの使用や頒布、修正、派生版の頒布をすることに制限を受けません。
参考情報
オープンソース年間サポートサービス
OpenStandiaではOSSを安心してご利用いただけるように、オープンソース年間サポートサービスをご提供しております。
サポートしているOSSは下記ページをご参照ください。