バージョンアップ情報
PyTorch情報
PyTorchとは
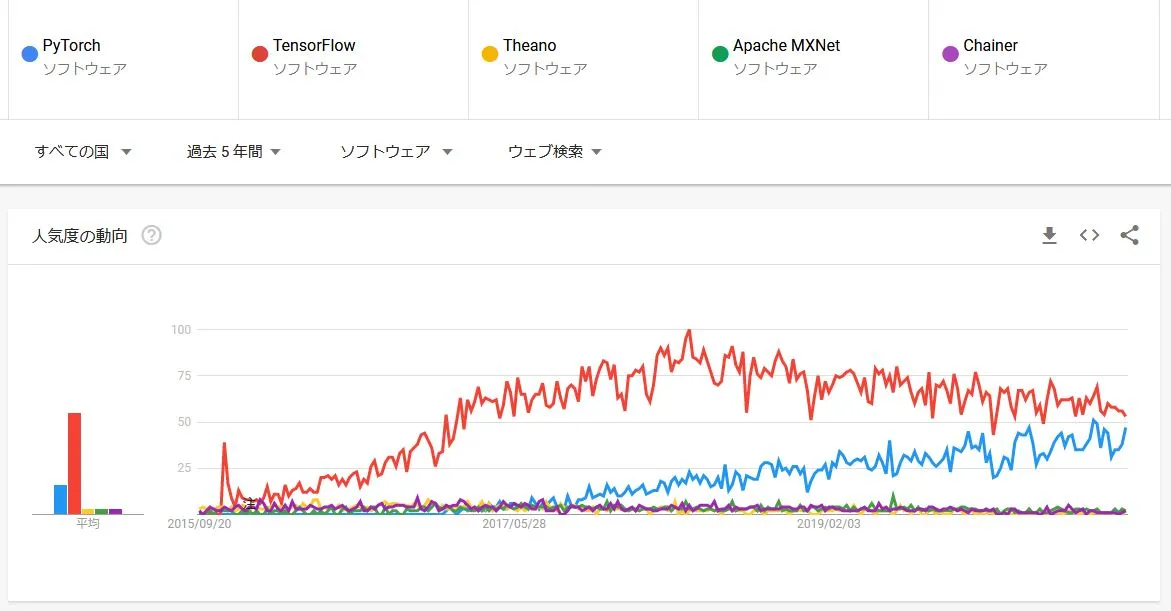
PyTorch(パイトーチ)は、オープンソースのPythonの機械学習フレームワークで、Facebookの人工知能研究グループにより開発されました。PyTorchは、Torch(トーチ)と呼ばれる「Lua」言語で実装された機械学習フレームワークを元に開発され、Pythonで実装できるようにしたものです。他の機械学習フレームワークと比較して公開されたのが新しいにも関わらず、TensorFlowに迫る人気を集めています。2020年09月時点のGoogle Trendsでの比較結果を見ると、圧倒的な人気であったTensorFlowに迫っていることが分かります。
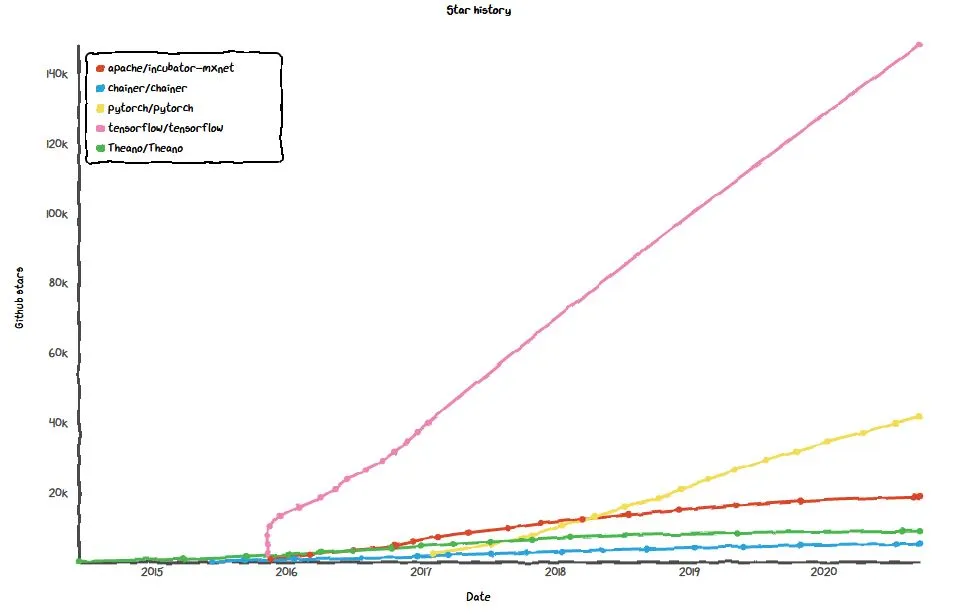
Githubのスター数もOSS全体で第3位のTensorFlow (1位Vue.js、2位react)には及びませんが、急激に増加しています。
以下のようにNumPyとほぼ同様の書き方で記述でき、それに加えてGPUによる計算もサポートしています。
>>> import torch
>>> x=torch.randn(4,3)
>>> x
tensor([[ 0.2627, 1.4585, 2.4710],
[ 0.4618, 1.2144, -0.6654],
[-0.8473, -2.4361, -0.2843],
[-0.3520, -0.4860, -0.1490]])
>>> x.dtype
torch.float32
>>> x.shape
torch.Size([4, 3])
>>> x.T
tensor([[ 0.2627, 0.4618, -0.8473, -0.3520],
[ 1.4585, 1.2144, -2.4361, -0.4860],
[ 2.4710, -0.6654, -0.2843, -0.1490]])
>>> x-1
tensor([[-0.7373, 0.4585, 1.4710],
[-0.5382, 0.2144, -1.6654],
[-1.8473, -3.4361, -1.2843],
[-1.3520, -1.4860, -1.1490]])
主な機能
PyTorchは、機械学習に関する基本的な機能を備えているだけでなく、同類のソフトウェアには存在しない(または、より優れた)機能や特徴があります。公式サイトでは「Key Features & Capabilities」として、以下を挙げています。
TorchScript
TorchScriptを使用すると、使いやすく柔軟性のある「Eagerモード」(※1)と、速度、最適化、機能面に優れたC++ランタイム環境でのグラフモードをシームレスに移行します。
import torch
class MyModule(torch.nn.Module):
def __init__(self, N, M):
super(MyModule, self).__init__()
self.weight = torch.nn.Parameter(torch.rand(N, M))
def forward(self, input):
if input.sum() > 0:
output = self.weight.mv(input)
else:
output = self.weight + input
return output
# Compile the model code to a static representation
my_script_module = torch.jit.script(MyModule(3, 4))
# Save the compiled code and model data so it can be loaded elsewhere
my_script_module.save("my_script_module.pt")
分散トレーニング
集合操作の非同期実行とピアツーピア通信のネイティブサポートを活用することにより、トレーニングを分散して実行することができ、パフォーマンスを向上させます。
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel
dist.init_process_group(backend='gloo')
model = DistributedDataParallel(model)
モバイル(実験的)
PyTorchは、PythonからiOSやAndroidへのデプロイまでのエンドツーエンドのワークフローをサポートしています。PyTorch APIを利用して、モバイルアプリケーションにMLを組み込むために必要な一般的な前処理や統合タスクを実行できます。
## Save your model
torch.jit.script(model).save("my_mobile_model.pt")
## iOS prebuilt binary
pod 'LibTorch'
## Android prebuilt binary
implementation 'org.pytorch:pytorch_android:1.3.0'
## Run your model (Android example)
Tensor input = Tensor.fromBlob(data, new long[]{1, data.length});
IValue output = module.forward(IValue.tensor(input));
float[] scores = output.getTensor().getDataAsFloatArray();
ツールとライブラリ
研究者と開発者の活発なコミュニティにより、コンピュータービジョンから強化学習まで様々な分野の開発をサポートする豊富なツールとライブラリが公開されています。
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
densenet = models.densenet161(pretrained=True)
inception = models.inception_v3(pretrained=True)
ネイティブONNXサポート
標準的なONNX(※2)形式でモデルをエクスポートします。これをインポートすることで、ONNX互換の異なるプラットフォーム、ランタイム、ビジュアライザなどの間でモデルの相互運用ができます。
import torch.onnx
import torchvision
dummy_input = torch.randn(1, 3, 224, 224)
model = torchvision.models.alexnet(pretrained=True)
torch.onnx.export(model, dummy_input, "alexnet.onnx")
C++フロントエンド
C++フロントエンドは、Pythonフロントエンドの設計とアーキテクチャに従うPyTorchへの純粋なC++インターフェイスです。高性能、低遅延、ベアメタルなC++アプリケーションの研究を可能にすることを目的としています。
#include
torch::nn::Linear model(num_features, 1);
torch::optim::SGD optimizer(model->parameters());
auto data_loader = torch::data::data_loader(dataset);
for (size_t epoch = 0; epoch < 10; ++epoch) {
for (auto batch : data_loader) {
auto prediction = model->forward(batch.data);
auto loss = loss_function(prediction, batch.target);
loss.backward();
optimizer.step();
}
}
クラウドパートナー
PyTorchは主要なクラウドプラットフォームでサポートされており、環境に依存しない開発と、事前に構築されたイメージによる簡単なスケーリング、GPUでの大規模なトレーニング、実稼働規模の環境でモデルを実行する機能などを提供します。
export IMAGE_FAMILY="pytorch-latest-cpu"
export ZONE="us-west1-b"
export INSTANCE_NAME="my-instance"
gcloud compute instances create $INSTANCE_NAME \
--zone=$ZONE \
--image-family=$IMAGE_FAMILY \
--image-project=deeplearning-platform-release
※1:「Define-by-Run」を実現するモード。「Define-by-Run」とは、データを流しながら計算グラフ(ニューラルネットの構造)の構築を行う手法です。
※2:ONNX(Open Neural Network Exchange)とは、フレームワーク間の相互運用性を実現するニューラルネットワークのモデル表現の標準フォーマットです。
類似プロダクト
PyTorchのようなOSSの機械学習のフレームワークは他にも多数あります。最も有名なものはGoogle社が開発したTensorFlowですが、AWSが公式にサポートを発表したMXNet、Microsoft社のCognitive Toolkit(CNTK)、JavaやScalaで開発可能なDeeplearning4j、中国百度社のPaddleなども同等の機能を備えています。
なお、「Define-by-Run」の画期的な仕組みをいち早く取り入れた国産の機械学習のフレームワークであるChainerは、2019年12月5日に新機能開発を終了し、PyTorchに移行することを発表しています。PyTorchの開発はChainerを参考にしているため、Chainerで実装されたコードをPyTorchへ移行することは比較的容易にできます。
動作環境
前提となる動作環境は、以下のとおりです。
OS
- Linux
- Arch Linux, 最小バージョン 2012-07-15
- CentOS, 最小バージョン 7.3-1611
- Debian, 最小バージョン 8.0
- Fedora, 最小バージョン 24
- Mint,最小バージョン 14
- OpenSUSE, 最小バージョン 42.1
- PCLinuxOS, 最小バージョン 2014.7
- Slackware, 最小バージョン 14.2
- Ubuntu, 最小バージョン 13.04
- macOS
- macOS 10.15 (Catalina) 以降
- Windows
- Windows 7 以降。Windows 10以降を推奨
- Windows Server 2008 r2 以降
Python
- Python 3.8 ~ 3.11
PyTorchのライセンス
PyTorchのライセンスはBSDライセンスです。BSDライセンスでは無保証であることの明記と著作権およびライセンス条文の表示を条件にコードの自由な改変・頒布が認められています。
参考情報
オープンソース年間サポートサービス
OpenStandiaではOSSを安心してご利用いただけるように、オープンソース年間サポートサービスをご提供しております。
サポートしているOSSは下記ページをご参照ください。