バージョンアップ情報
scikit-learn情報
scikit-learnとは
scikit-learn(サイキット・ラーン)は、Pythonで実装されたオープンソースの機械学習ライブラリーです。分類、回帰、クラスタリングなどの非常に多くのアルゴリズムを実装しており、機械学習モデルを作成する上で必要不可欠なライブラリーと言えます。scikit-learnのコミュニティは非常に活発であり、常に開発と改良が続けられています。使い方もシンプルで初学者でも簡単に扱うことができます。scikit-learnは、Pythonの数値計算ライブラリーであるNumPyやSciPyとやり取りするよう設計されており、データを表形式で扱うことができるPandasや可視化を行うためのMatplotlibなどのライブラリーとともに使用します。
scikit-learnには実験的な用途に使用できるいくつかのサンプルのデータも含まれています。例えば、0から9の10種類の手書きの数字の画素データや、糖尿病患者442人の検査数値とその1年後の疾患進行状況をまとめたデータセットなどが含まれています。これを使って、回帰問題や分類問題のための機械学習モデルを構築することができます。
このサンプルの中にあるアヤメの特徴を表すデータを使用して、アヤメの花を分類する例を紹介します。以下の4つのアヤメの特徴をもとに、K-meansというアルゴリズムを用いてアヤメの品種を分類します。
- がくの長さ
- がくの幅
- 花弁の長さ
- 花弁の幅

3種類(versicolor、virginica、setosa)に分類するモデルを作成し、実際の結果と比較したい場合、以下のようなコードで実現できます。
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.cluster import KMeans
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
estimator = KMeans(n_clusters=3)
estimator.fit(X)
fig = plt.figure(figsize=(18, 8))
ax = fig.add_subplot(121, projection='3d', elev=45, azim=135)
ax.scatter(X[:, 3], X[:, 0], X[:, 2],
c=estimator.labels_.astype(np.float), edgecolor='k')
ax.set_xlabel('Petal width')
ax.set_ylabel('Sepal length')
ax.set_zlabel('Petal length')
ax.set_title('KMeans 3 clusters')
ax.dist = 12
ax = fig.add_subplot(122, projection='3d', elev=45, azim=135)
for name, label in [('Setosa', 0),
('Versicolour', 1),
('Virginica', 2)]:
ax.text3D(X[y == label, 3].mean(),
X[y == label, 0].mean(),
X[y == label, 2].mean() + 2, name,
horizontalalignment='center',
bbox=dict(alpha=.2, edgecolor='w', facecolor='w'))
y = np.choose(y, [2, 1, 0]).astype(np.float)
ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=y, edgecolor='k')
ax.set_xlabel('Petal width')
ax.set_ylabel('Sepal length')
ax.set_zlabel('Petal length')
ax.set_title('Ground Truth')
ax.dist = 12
fig.show()
出力は次のようなグラフになります。
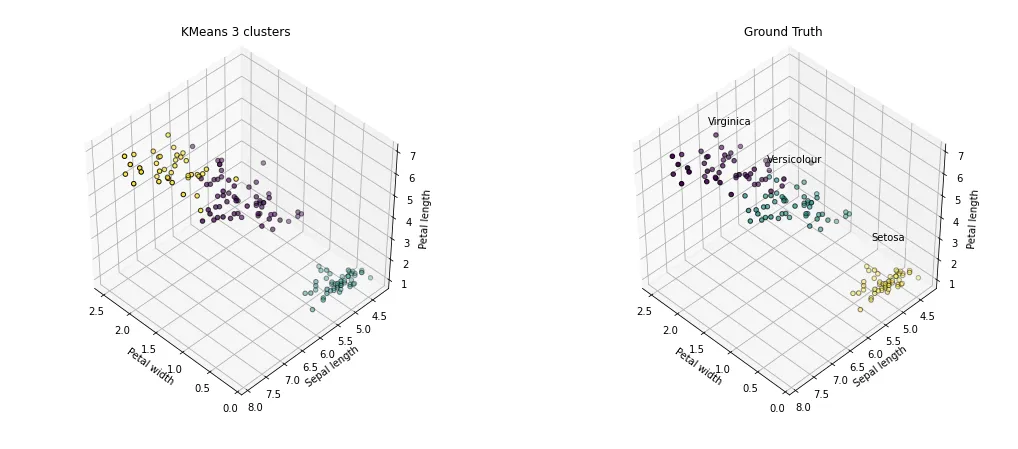
K-Meansにより、ほぼ正しく品種の分離ができていることが分かります。
主な特徴
主な特徴は以下のとおりです。
|
機能 |
詳細 |
|---|---|
|
教師あり学習 |
以下のアルゴリズムをサポート
|
|
教師なし学習 |
以下のアルゴリズムをサポート
|
|
モデルの選択と評価 |
以下の機能をサポート
|
|
検査 |
以下の機能をサポート
|
|
可視化 |
様々なプロット・ユーティリティーをサポート |
|
データセット変換 |
以下の機能をサポート
|
|
データセットロードのためのユーティリティー |
以下の機能をサポート
|
|
計算性能 |
計算量をスケールさせるための並列化、リソース管理、設定が可能 |
|
モデルの永続化 |
相互運用可能なフォーマットでモデルを永続化可能 |
主な特徴は以下のとおりです。
- 高機能
前述したとおり、scikit-learnは非常に高機能です。機械学習をする上で必要な機能が揃っています。ただし、GPUのサポートとディープラーニングや強化学習はscikit-learnだけでは実行できません。その場合は、Keras/TensorFlowやPytorchなどを利用します。
- 高品質
実験的なコードをリリースすることはめったになく、機能を追加する場合は厳格なレビューが行われるため非常に高品質で、バグが少ないといえます。
- 簡単かつ柔軟
一貫性のあるシンプルなAPIを提供しており、学習が容易なだけでなく、モデルや正規化のアルゴリズムなどを柔軟に変更できます。インストールもコマンド1つで実行できます。
- 利用実績
オンラインのドキュメントがとても充実しており、世界中の多くの人に利用されています。
類似プロダクト
OSSの機械学習のライブラリーは他にも多数ありますが、scikit-learnほどの高機能なライブラリーは他にはありません。この分野ではデファクトスタンダードなOSSと言えます。
動作環境
scikit-learn をインストールするには、さまざまな方法がありますが、オペレーションシステム、または Python ディストリビューションによって提供される最新リリースをインストールすることが推奨されています。
最新の機能を試したいユーザや、プロジェクトに貢献したいユーザはソースからビルドすることも可能です。
scikit-learnの公式インストールガイドは下記です。
scikit-learnのライセンス
scikit-learnのライセンスは、BSDライセンスです。無保証であることの明記と著作権およびライセンス条文の表示を条件に、オブジェクトコードの自由な改変・頒布が認められています。
参考情報
オープンソース年間サポートサービス
OpenStandiaではOSSを安心してご利用いただけるように、オープンソース年間サポートサービスをご提供しております。
サポートしているOSSは下記ページをご参照ください。