
Apache Hadoopの概要
Hadoop(ハドゥープ)は大規模データの蓄積、加工を分散して処理するフレームワークです。
大規模データを処理するために、従来はデータウェアハウスなど専用の製品を使う必要がありました。
しかし、これらは非常に高価で、システムのスケールアップにも限界があります。
Hadoopはこのようなデータ処理を、一般的なサーバマシンを複数つなげ合わせる(スケールアウト)ことで実現し、増え続けるデータ量に対して、処理性能を維持することが可能なシステムです。
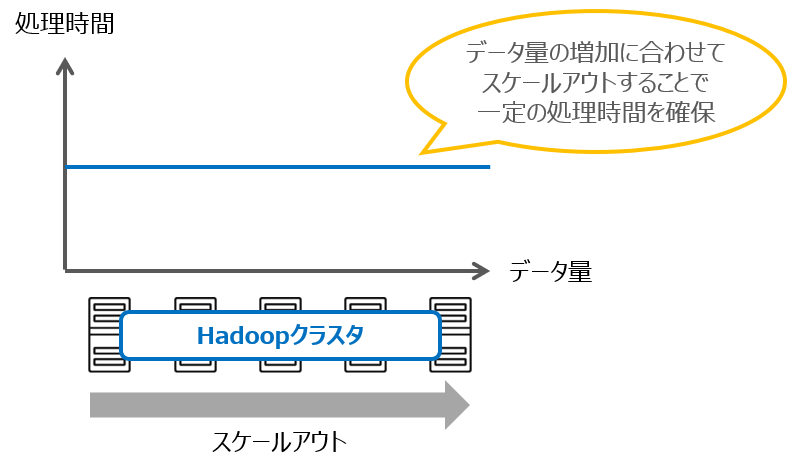
Hadoopシステムは複数台に分散していることでシステムの柔軟性を高めています。
一般的なサーバマシン群から構成できるため、ハードウェアの調達が容易です。
また1台のサーバに障害が発生しても他のサーバでシステムの継続が可能です。
処理性能を向上させたい場合には、Hadoopクラスタにサーバを追加するだけで済みます。
このような特徴から、耐障害性と処理性能を兼ね備えたシステムといえます。
Hadoopの主要モジュール
Hadoopは2系以降、以下の4つのCoreモジュールから成り立っています。
- Hadoop Distributed File System (HDFS)
- Hadoop MapReduce
- Hadoop Common
- Hadoop YARN
HDFS (Hadoop Distributed File System)
Hadoopの分散ファイルシステムです。
ユーザからは1つの大きなファイルシステムとして見えますが、各ノードにまたがってファイルを保存しています。
1つのノードに障害が起こってもデータの欠損が無いように、デフォルトで3つのノードに同じデータを保持(3重化)しています。
MapReduce
HDFSに保存されたデータに対して、並列分散的に処理を実行するためのフレームワークです。
MapReduceの分散処理はMapフェーズとReduceフェーズに分かれています。
Mapフェーズでは各スレーブノードのデータに対して並列に処理を行い、Reduceフェーズでは、Mapフェーズの処理結果に対する集約が行われます。
Hadoop Common
Hadoopの機能をサポートするユーティリティ群です。
YARN (Yet Another Resource Negotiator)
分散処理のジョブスケジューリングとリソース管理を行うコンポーネントです。
MapReduceのみならず、Spark、Tez などの他の分散処理フレームワークのリソース管理も可能としています。
Apache Sparkの概要
「Spark」(スパーク)は、大量データに対して高速に分散処理を行うフレームワークです。
複数のサーバを用いたクラスタ構成を組むことが特徴で、データサイズやニーズの変化に合わせてサーバを追加(スケールアウト)することにより、高いシステム拡張性と処理性能の維持向上を実現しています。
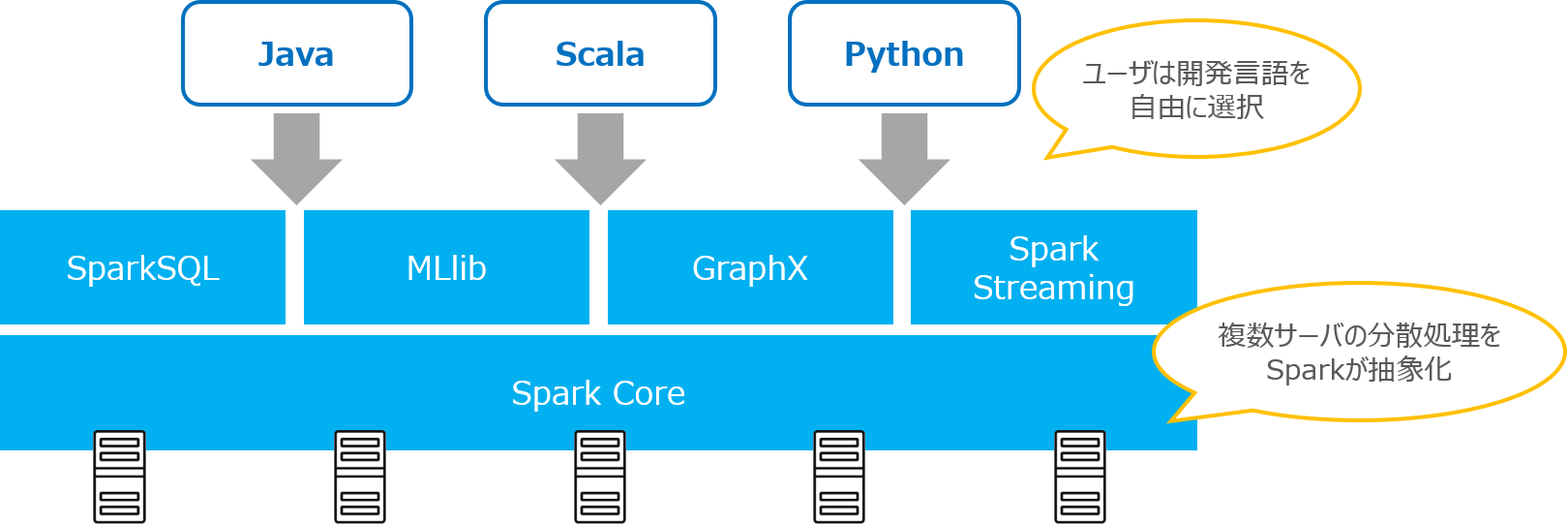
Sparkは分散処理の仕組みを抽象化しているため、利用者は簡単なコードを実行するだけで、何十台・何百台ものサーバで、同時に演算処理を行うことができます。
データソースとしてはHDFSや各種DB(JDBC接続)が利用できます。
開発APIにはJava、Scala、Pythonなどが用意されており、利用者は得意な開発言語を選択することができます。
また、クラスタ上のデータをSQLとして処理できる「Spark SQL」、機械学習のための「MLlib」、グラフ処理のための「GraphX」、ストリーミング処理のための「Spark Streaming」といったコンポーネントライブラリを保持しています。
Apache Spark の特徴
Sparkには以下の特徴があります。
- 分散キャッシュであるRDD(Resillient Distributed Datasets)により、繰り返し処理で高パフォーマンスを実現
- インメモリでの高速処理と、Hadoopと同様の高い耐障害性を確保
- 汎用的なプログラミング言語とSQLの記述による高い開発生産性
Apache Spark と Apache Hadoop
SparkはHadoopクラスタと連携することにより、最適化されたシステムとして動作します。
1つのSparkアプリケーションがクラスタ環境を占有しないように、YARNのリソース管理、スケジュール管理に従って適切に処理されます。
また、HDFSを構成するサーバ上でSparkは動作するため、データソースへのアクセスが分散され最適化されます。

Apache Spark の活用事例
◆ 顧客ビジネス:
分析領域の拡大による商品・サービスの付加価値向上・シェア拡大
◆ 活用シーン:
構造化されたERPやCRMのデータに加えて、アクセスログやSNS等の非構造データを利用
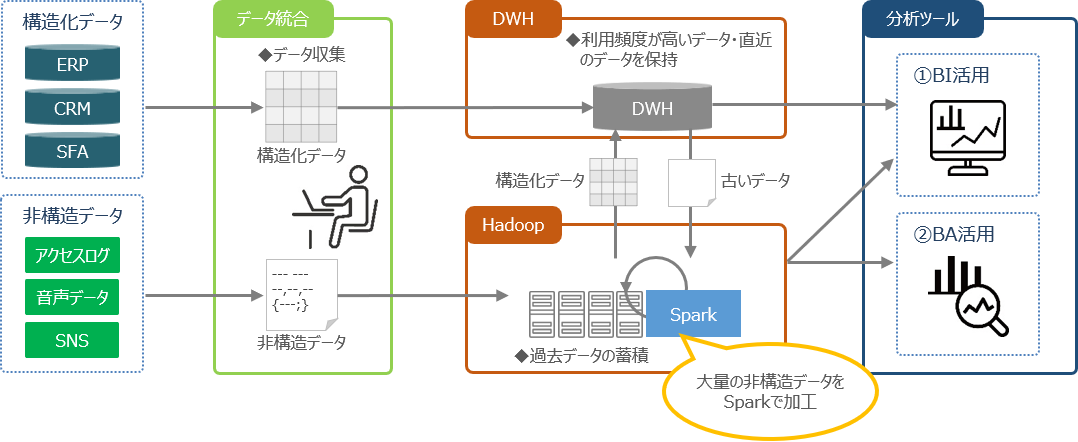
◆ 導入効果:
● ITコストを適正化
⇒ DWHとのハイブリット構成としてストレージコストを削減するとともに、データ量に合わせて柔軟にスケールアウトすることで将来のITコスト適正化を実現します。
● 分析利用の拡大
⇒ 今まで利用できなかったログや、お客様の声などの非構造データの活用により、効果的なマーケティングや商品開発を実現します。
OpenStandiaサービス
OSS利用の課題を解決し、企業にもたらすOSSのメリットを感じて頂くためのさまざまなサポート&サービスメニューをご用意しています。