
Apache Kafka の概要
「Kafka」(カフカ)とはシステム間のデータを一時的に保持し、受け渡しを行う分散メッセージキューです。
Kafkaは複数台のサーバでクラスタを構成して分散処理を行うため、高いスループットを発揮します。
また、サーバ追加(スケールアウト)により、処理性能とメッセージ保持容量に対する高い拡張性を有しています。
一般的なクライアント / サーバシステム においては、サーバがクライアントにデータを送信する「Push型」、クライアントがサーバにデータを取得しにいく「Pull型」がありますが、KafkaはPull型(Publish / Subscribeモデル)の分散メッセージキューとなります。
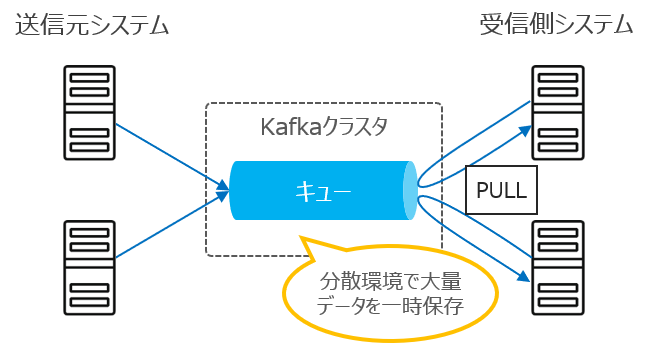
Kafkaの導入によりシステム間のデータの受け渡しを非同期化することで、送信元システムからの急激なデータ増加に伴うシステムの負荷上昇を抑制することが可能になります。
Apache Kafka の特徴
Kafkaには以下の特徴があります。
- 1台のKafkaサーバで秒間10万メッセージ(20MB)以上の送受信が可能
- データ量やメッセージキューの数に応じて柔軟にシステム拡張(スケールアウト)が可能
- Kafkaサーバがメッセージを永続化して連携先システムへの到達を保証
Apache Kafka を利用したストリーミングシステム
Kafkaはシステム間の交通整理を行うデータハブとしての使い方の他に、ストリーミングシステムにも活用されています。
フロントシステムから送信されてくる大量のリアルタイムデータを処理するために、Hadoop / Spark Streamingと連携したストリーミングアプリケーションの構成が多く利用されています。
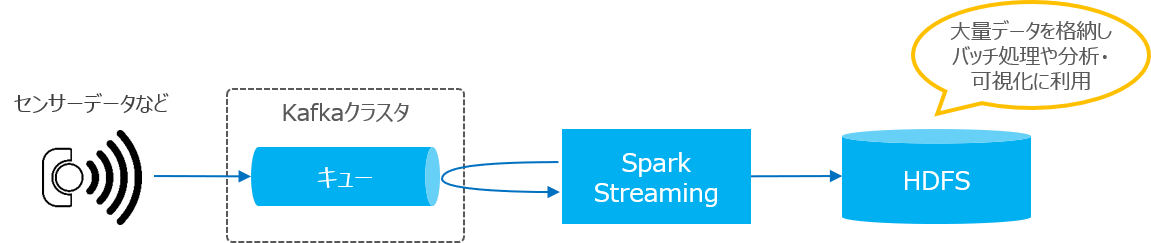
Apache Kafka の活用事例
ケース1
◆ 顧客ビジネス:
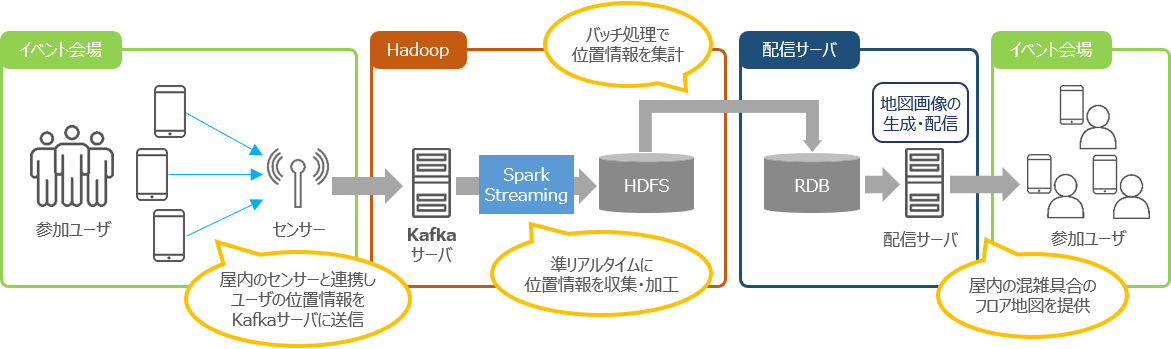
イベント会場における準リアルタイムでの混雑状況の可視化・予測
◆ 活用シーン:
会場内のセンサーを利用してリアルタイムに位置情報収集
1分間に数万メッセージ送信される情報をSpark Streamingでマイクロバッチ処理
◆ 導入効果:
● 会場内のユーザ位置を準リアルタイムに把握
⇒ 収集・分析した結果を可視化して提供することにより、イベント参加者が効率的なブース巡回が可能に
● ユーザ位置情報の定期的な収集と分析
⇒ イベント会場運営に対して、今後の会場動線検討に活用
ケース2
◆ 顧客ビジネス:
製造業における電子機器の製造販売
◆ 活用シーン:
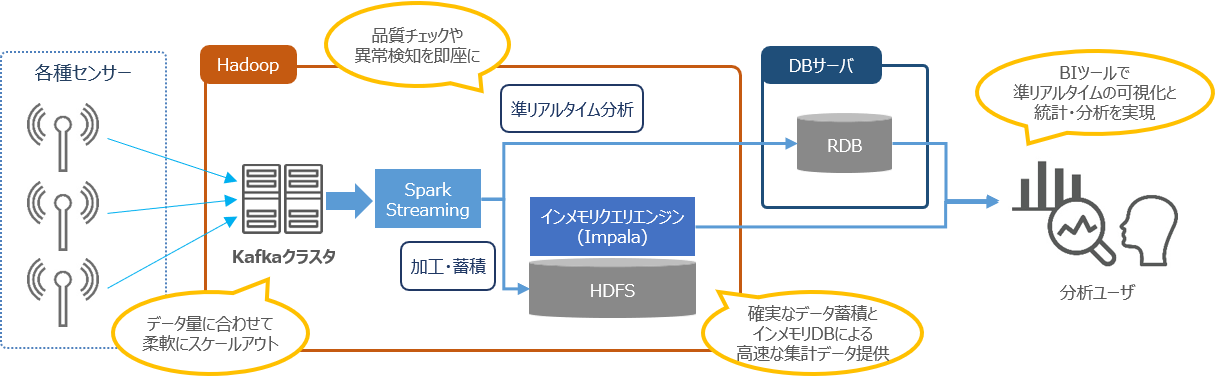
工場内の製造ラインや装置内のセンサーから、大量かつ高頻度で発生するセンサーデータの
リアルタイム監視による異常検知や、データ分析による製造品質の改善
◆ 導入効果:
● データ量や処理性能に合わせたスケーラブルな拡張による運用コストの適正化
⇒ 多数のセンサーから大量・高頻度に発生するデータを適切に蓄積・活用
● リアルタイムな異常検知による問題の早期解決、データ分析での製造品質改善
⇒ ストリーム処理でデータを準リアルタイムで監視すると共に、データ加工や集計処理等をバッチ処理で高速に実行し、BI/BAツールへ情報提供
OpenStandiaサービス
OSS利用の課題を解決し、企業にもたらすOSSのメリットを感じて頂くためのさまざまなサポート&サービスメニューをご用意しています。