RAGとは?検索拡張生成の仕組みとLLMとの違い、活用事例をわかりやすく解説
2026/01/30
近年注目を集めている「RAG(検索拡張生成)」とは、大規模言語モデル(LLM)に外部データの検索能力を組み合わせ、より正確で根拠のある回答を生成する技術です。LLMは学習データの範囲に知識が固定されるため、社内文書のような独自情報や、最新のニュース・製品情報を反映しにくいという課題がありました。
RAGは外部のデータベースやドキュメントを検索し、必要な情報を生成プロセスに組み込むことで、この課題を解決します。結果として、LLMは学習時点を超えた知識を活用でき、信頼性の高い応答を提供できるようになります。
本記事では、RAGの基本的な仕組みから、LLMやファインチューニングとの違い、導入メリット、ビジネス活用事例までをわかりやすく解説します。
生成AIの詳細については、こちらをご参照ください。
生成AIとは?種類や仕組み、ビジネス活用事例をわかりやすく解説
目次
RAGとは?ファインチューニングやLLMとの違いを解説
RAGとは「Retrieval-Augmented Generation(検索拡張生成)」の略称で、LLMと検索機能を組み合わせた技術を指します。回答を生成する際に、検索システムが外部データベースから関連情報を検索し、その情報を参照・活用してLLMの回答精度を高めます。
RAGの特徴
RAGの最大の特徴は、LLMが学習していない情報や最新の社内データにもとづいて、正確な回答を生成できる点です。RAGは外部データベースを参照する仕組みのため、モデル自体の再学習は必要ありません。参照元となる外部データベースや文書ファイルを更新し、状況に応じてインデックスを再構築するだけで最新情報を反映することが可能です。
これまでLLM単体では社内固有の知識を十分に活用することが難しいとされてきましたが、RAGの導入によってその課題を解決できます。社内ルールを反映したチャットボットの構築や、カスタマーサポートの回答精度の向上など、回答に正確性が求められる業務への応用が進んでいます。
RAGとLLMとの違い
LLM(大規模言語モデル)は、ディープラーニングを用いて膨大なテキストデータを事前に学習した、生成AIモデルです。文脈を深く理解し、人間のような自然な文章を生成する能力に優れています。
しかし、LLMが扱える知識は学習データが収集された時点で固定されており、学習範囲外の最新情報や非公開の社内データについては対応できません。こうした課題に対応するために登場したのがRAG(Retrieval-Augmented Generation、検索拡張生成)です。RAGは、ユーザーの質問内容に応じて外部のデータベースや社内ドキュメントなどから関連する情報を検索し、その情報をLLMに入力して回答を生成する仕組みです。これにより、LLM単体利用では難しい、リアルタイム性やカスタマイズ性の高い知識活用が可能になります。
| RAGを利用する場合 | LLM単体を利用する場合 | |
|---|---|---|
| 仕組み |
ユーザーの質問に対し、まず外部データベースから関連情報を検索・抽出し、その内容をLLMに入力して回答を生成する。 |
事前に学習したテキストデータだけをもとにLLMが回答を生成する。 |
| 特徴 |
最新情報や社内独自データなど、外部知識の活用が可能。 |
学習時点の知識のみ参照。公開情報が中心で、最新動向や社内情報は反映されない。 |
たとえば、ユーザーが質問をすると、RAGを用いたシステムでは最初に外部データベースから関連文書を検索し、その情報がプロンプトとしてLLMに追加されます。LLMはこの追加情報を利用することで、より文脈に即した回答を生成できるのです。
RAGとプロンプトエンジニアリングとの違い
プロンプトエンジニアリングとは、LLMへの指示文(プロンプト)の質や形式を最適化し、回答の精度と信頼性を向上させる技術です。具体的には、LLMに対して「あなたは優秀なコンサルタントです」のように役割や条件、要素を指定して出力を誘導する方法が該当します。専門的な知識がなくても活用しやすい反面、LLMが元々持つ学習データに依存するため、回答精度の向上には限界があります。
一方、RAGはLLMが持っていない外部の専門知識や最新データを、プロンプトに追加することで回答の正確性を高めます。つまり、プロンプトエンジニアリングは「LLMの考え方(出力方法)」を改善するのに対し、RAGは「LLMが参照できる知識源」を外部に広げます。RAG導入後も、より質の高い回答を引き出すために、プロンプトエンジニアリングの技術を組み合わせて使われることが一般的です。
RAGとファインチューニングとの違い
特定のデータセットに合わせて、学習済みのLLMの一部または全部を再トレーニングし、パラメーターを微調節することをファインチューニングと呼びます。ファインチューニングを用いると特定のタスク向けにLLMを調節できますが、学習プロセスには多くの計算リソースと時間が必要です。また、新しい情報を反映させるには、その都度ファインチューニングをやり直す必要があるため、コストの高い手法といえます。
対して、RAGはLLMのモデル自体には手を加えず、外部データベースを参照させるだけのため、モデルの再学習にかかるコスト・時間が不要です。RAGとファインチューニングはどちらもLLMの専門性を高めますが「初期費用や運用コストを抑えたい場合」や「情報が頻繁に更新される場合」には、RAGが有効な選択肢となります。
RAGの仕組み
RAGは、検索・拡張・生成の3つのフェーズから構成される技術です。RAGの仕組みを理解するために、それぞれのフェーズについて説明していきます。
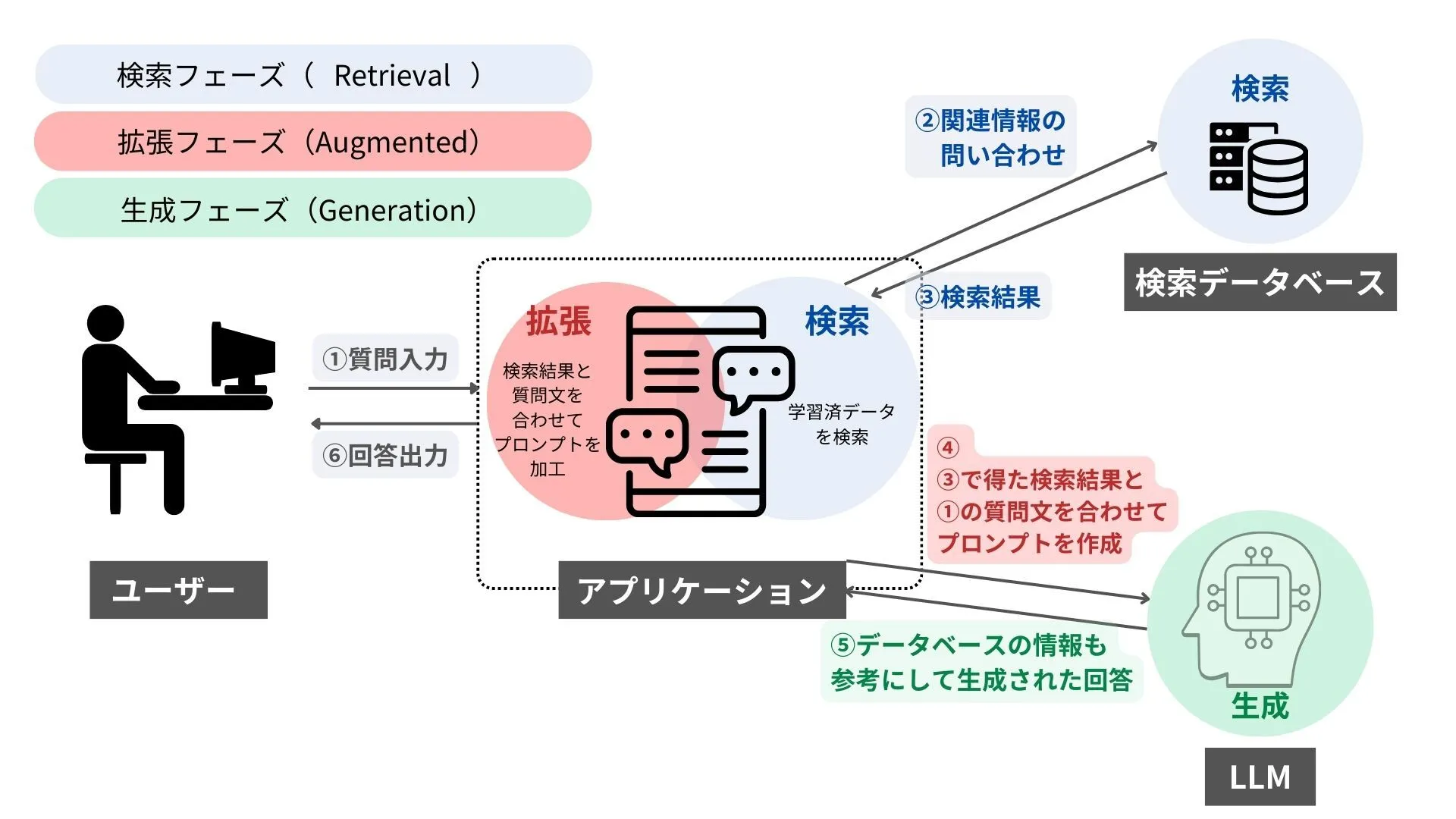
検索フェーズ(Retrieval)
RAGの最初のステップである検索フェーズ(Retrieval)は、外部のデータベースやドキュメントから、ユーザーの質問に関連性の高い情報を検索・抽出するプロセスです。検索フェーズで主に使用される検索方式は、以下の3つです。
- ベクトル検索:入力したデータをコンピュータが扱いやすい「ベクトル」に変換し、意味的な類似度にもとづいて効率的に関連情報を抽出する
- キーワード検索:入力した単語やフレーズをもとに、文字列の一致や類似度にもとづいて検索する
- ハイブリッド検索:ベクトル検索とキーワード検索など、複数の方式を組み合わせて検索の精度を高める
RAGでは、検索・抽出した情報をもとに回答を生成するため、検索フェーズは回答の精度を左右する重要なプロセスとなります。
拡張フェーズ(Augmented)
拡張フェーズ(Augmented)は、検索フェーズで見つけ出された関連情報を、LLMへのプロンプトに追加するステップです。LLMが回答を生成しやすいように、検索結果の情報を要約・整形・構造化して加工します。
たとえば、ユーザーが「会社の規則について教えてください」という質問をアプリケーションに送った場合、検索フェーズにて就業規則などのドキュメントを検索します。そして、拡張フェーズでは「以下のドキュメント情報にもとづいて、会社の規則について教えてください」という形にプロンプトを変換し、ドキュメントの内容を含めてLLMへ送信する流れです。
生成フェーズ(Generation)
生成フェーズ(Generation)では、拡張フェーズで準備されたプロンプトを受け取ったLLMが、最終的な回答を作成します。検索で得られた情報を単に提示するのではなく、質問の意図に沿う形で情報を要約または統合し、LLMの高い自然言語処理能力を活かして人間が理解しやすい形式に再構成します。
つまり、RAGは検索によって信頼性の高い情報を取り込み、LLMの優れた文章生成能力と組み合わせることで、正確な文章が出力されるのです。
RAGが注目される背景
RAGが注目を集めているのは、LLMが抱える「知識の限界」と「情報の鮮度」という課題を解決し、実用性を高める技術だからです。LLMの知識は、学習データが収集された時点で固定されています。そのため、企業独自の業務ルールや製品知識、最新情報に対応できず、高度な業務効率化や意思決定支援に活用することは困難でした。
RAGは外部の知識源を接続することで、LLMを「学習済みの静的AI」から「知識をリアルタイムで更新できる動的AI」へと進化させます。ハルシネーション(AIが誤った回答を生成する現象)のリスクを抑えつつ、企業の専門知識を活かした高精度なチャットボット構築などが可能になります。
結果として、RAGはAIを時代遅れにしないための根幹技術と言えるでしょう。企業や研究、教育など、多種多様な分野において、決定的な価値をもたらすことができます。
RAGを導入するメリット
RAGを導入することは、LLM単体での利用と比較して企業において多くのメリットをもたらします。ここからは、RAGを導入してビジネスに活用するメリットを4つ紹介します。
ハルシネーションが減少する
RAGを導入する大きなメリットの1つに、AIが誤った情報を生成する「ハルシネーション」のリスクを減らせる点があります。LLMは一度学習が完了すると知識が固定されるため、学習データが古い、または不正確である場合、間違った回答を生成してしまうことが少なくありません。
RAGの仕組みでは、外部データベースから検索された情報がプロンプトとしてLLMに与えられます。リアルタイムで情報が更新されるWebサイトや、信頼性の高い学術データベースなどを参考にすることも可能です。
この仕組みにより、LLMは「根拠となる情報」や「最新の情報」にもとづいて回答を生成し、不正確な内容を提示するリスクを抑えられるでしょう。さらに、RAGは回答の際に参照元のドキュメントやデータを提示できるため、ユーザーは回答の信頼性を自分で検証することが可能です。
最新情報を反映しやすい
RAGは外部データベースの情報をリアルタイムで参照するため、LLMが抱える「情報の鮮度」の問題を解消します。企業がRAGシステムを導入する際は、参照元となるデータベースを最新のマニュアルや市場データなどで随時改訂するだけで、情報の更新が完了します。
特に、法規制や業界標準が頻繁に変わる分野での利用において、RAGのメリットは大きいでしょう。
モデルサイズや学習コストを削減できる
RAGを導入すると、LLMのファインチューニングにかかる莫大なコストを回避できます。ファインチューニングはRAGと同様にLLMの専門性を高めますが、モデル自体を再学習する仕組みです。再学習には高性能なGPUや、高品質かつ大量な学習データが必要であり、コストと時間を要します。
一方、RAGの導入で必要となる外部データベースの構築や更新にかかるコストは、モデルの再学習費用と比較して安価です。汎用的なLLMをそのまま使うため、モデルのサイズが肥大化する事態や、それに伴うストレージやメモリの要求が増えるといったリソース面での問題も防げます。
プロンプトエンジニアリングにかかる負担が軽減する
RAGには、LLMに与えるプロンプトのサイズを最適化できるというメリットもあります。従来のLLM利用では、質問の背景情報や参考資料をプロンプト内に大量に含まねばならず、プロンプトが長くなりすぎる傾向がみられました。
RAGでは、外部の知識ベースから質問に関連する情報を自動的に検索・補完するため、プロンプトに詳細な情報を記載する必要性が少なくなります。結果として、ユーザーはより簡潔なプロンプトで高品質な回答を得ることが可能となり、プロンプトエンジニアリングにかかる負担の軽減が見込めます。
RAG導入時の検討事項
RAGをビジネスへ導入するためには、いくつかの検討すべき事項があります。外部データを利用する仕組み上、データの質やシステム全体の安定性については、特に注意が必要です。
セキュリティ・プライバシー対策が必要となる
RAGは、企業の非公開の専門データを参照して回答を生成する場合、セキュリティとプライバシー対策が欠かせません。RAGシステムが不正アクセスやサイバー攻撃の標的となった場合、機密情報や個人情報の漏えいなどを引き起こす危険性が高まります。また、不正なプロンプトを紛れ込ませて、生成AIの誤作動を引き起こす「プロンプトインジェクション(PI)」という攻撃手法も存在します。
プロンプトインジェクションの主な対策は、以下のとおりです。
- ユーザーからの入力を検証・フィルタリングする
- RAGの検索結果を検証する
- LLMがアクセスできる範囲を業務上の必要最低限にとどめる
- LLMの監視体制を構築する
- LLMガードレール(LLMの入出力を監視・制御する技術)を導入する
外部データベースへのアクセス制御の厳格化や、多要素認証の導入といった対策もセキュリティリスクの軽減につながります。
回答内容がデータの質に左右される
RAGを用いて生成した回答の正確性や質は、参照元となる外部データに左右されます。加えて、単にデータを用意するだけでなく、ドキュメントを検索・理解しやすいように適切なサイズに分割するなど、データの切り取り方にも配慮することが重要です。
さらに、RAGを導入する際は最新の情報を参照できるように、マニュアルや規定を定期的に更新し、改訂履歴を管理することが不可欠です。データの一貫性を保つには、重複または矛盾する記述を排除する作業も発生します。
LLM単体での使用よりも処理時間が長くなりやすい
RAGにはLLMが回答を生成する前に、外部データベースから関連情報を検索・抽出するという追加のステップが発生します。そのため、LLM単体でプロンプトを処理する場合と比較して、回答の生成までにかかる時間が長くなりやすいです。
特に、参照するデータ量が非常に多い場合や、データベースの応答速度が遅い場合は、処理時間の延長が顕著になるかもしれません。処理速度を改善するには、質問の内容に応じてLLM単体とRAGを使い分けることが有効です。たとえば、一般的な知識に関する質問や迅速な応答が求められる場合はLLM単体で処理し、専門的なデータにもとづいた回答が求められる場合はRAGを活用するなど、ハイブリッドな運用体制も選択肢のひとつです。
RAGのビジネス活用事例
RAGのビジネス活用事例を5つ紹介します。RAGの導入を検討している方は、ぜひ参考にしてみてください。
社内ルールにもとづくチャットボットの構築
RAGは企業の社内ルールや規定にもとづいた、高精度なチャットボットの構築に役立ちます。従来のLLMを利用したチャットボットでは、作成された時点のルールしか回答できないという制約がありました。しかし、RAGを導入することで、人事規定や経費精算ルール、情報セキュリティガイドラインなどのドキュメントをデータベースに格納すれば、最新の情報にもとづいて回答を生成できます。
たとえば「リモートワーク手当の申請方法は?」と質問すると、RAGを用いて最新の就業規則ドキュメントから該当箇所が検索され、正確なルールと手順を回答します。チャットボットの活用により、総務・人事部門に問い合わせる手間が削減され、業務効率が向上するでしょう。
カスタマーサポートの高精度化
製品マニュアルやFAQ、過去の顧客対応ログといった膨大なサポートドキュメントを参照することで、RAGはカスタマーサポートの精度を高めます。サポート担当者が手作業で資料を探す時間を減らし、顧客へ一貫性のある正確な情報を提供できるようになる点が魅力です。
また、カスタマーサポートのチャットボットにRAGを組み込むと、専門性の高い問い合わせにも対応可能となり、顧客満足度の向上とサポートコストの削減を両立できます。
業務マニュアルの要約
RAGは、企業が保有する長大な業務マニュアルや技術文書を、効率的に要約することが可能です。LLMの高い言語処理能力と、RAGの正確な情報検索が組み合わさり、高品質な要約が実現します。
特に、新しいプロジェクトが始まる際や、新入社員の研修時などに効果を発揮するでしょう。業務マニュアルの要約により、必要な情報に短時間でアクセスできるようになり、マニュアルを最初から最後まで読み込む負担が軽減されます。
レベル応じた学習・研修プランの提供
教育や研修の分野において、受講者のレベルや進捗状況に合わせた学習コンテンツ・プランを生成するために、RAGが活用されています。受講者の過去のテスト結果や学習履歴を外部データベースに格納し、そのデータを参照した上で学習プランを作成する仕組みです。企業内での研修はもちろん、教育現場での活用も見込めるでしょう。
受講者は画一的なカリキュラムではなく、自分だけのパーソナライズされた学習計画を受け取るため、学習効果の最大化が図れます。
非公開の社内データの分析
RAGは、外部公開されていない企業のデータ分析を、安全に行うために有効です。LLMをファインチューニングするわけではないため、機密データがモデルの学習データとして流出するリスクを抑えられます。
具体的には、市場調査レポートや非公開の営業記録などデータベースに格納し「市場における当社の製品の強みと弱みを分析せよ」という指示を与えると、情報にもとづいた分析や傾向予測を短時間で実行します。分析をRAGに任せることで人件費が削減できるほか、人間が見落としがちな新しい傾向や相関関係を抽出することも可能です。
RAGの構築に必要なもの
RAGシステムを構築するために必要となる4つの要素について、以下の表にまとめました。
| 要素 | 役割 | 主なOSS/例 |
|---|---|---|
|
データソース |
LLMに参照させたい情報を格納する場所。 |
-(社内文書、規定、FAQなど) |
|
ベクトルDB |
データを「ベクトル」に変換して格納し、高速で関連情報を検索するデータベース。 |
・FAISS |
|
LLM |
RAGを用いて参照した情報にもとづき、最終的な回答を生成するAIモデル。 |
・Llama |
|
オーケストレーション |
検索・拡張・生成のプロセスを制御し、要素間の連携を担う仕組み。 |
・LangChain |
RAGシステムを構築するには「LLM」に加えて、知識を格納・検索するための「データソース」や「ベクトルDB」、各技術を連携させる「オーケストレーション」が必要です。なお、RAGに関連するOSSを活用することで、開発者は複雑なシステムを構築する手間を削減できます。
OSSの詳細については、こちらをご参照ください。
OSS(オープンソースソフトウェア)とは?メリットと導入時の注意点
RAGの精度を高める方法
RAGの精度は、データ・検索・生成の3つの品質に左右されます。それぞれの品質を高める方法は、以下のとおりです。
| 品質を高める方法 | |
|---|---|
| データ品質 |
・ノイズ除去・正規化:誤字脱字や表記ゆれを修正し、データを一貫した形式に整える。 |
| 検索品質 |
・適切な分割サイズ:検索しやすいように、テキストを適切なサイズに分割する。 |
| 生成品質 |
・プロンプトテンプレートの設計:LLMに渡すプロンプトに、指示を含めるためのテンプレートを設計する。 |
RAGの精度を向上させるために、参照するデータの質と検索の効率を最適化することが重要です。
注目すべきRAGの将来の見通し
RAGは今後、LLMの実用性を高める技術として、さらに発展していくと見られています。例として、現在主流のテキストベースのRAGに加え、今後はマルチモーダルRAGへの発展が期待されています。マルチモーダルRAGとは、画像や音声、動画など複数のデータ形式から情報を検索・生成するための技術です。
また、RAGは「情報を探すAI」から「知識を育てるAI」へ進化していくと予測されます。参照元のデータの信頼性を判断したり、不足している知識を自律的に検索・追加したりするなど、能動的に知識を管理・改善する機能が組み込まれていくでしょう。
まとめ
RAGの最大の特徴は、LLM自体を再学習するコストを回避しながら、外部データベースを更新するだけで社内情報・最新情報に対応できる点です。情報の正確性や信頼性が向上するため、ハルシネーションの防止にもつながります。RAGが持つ柔軟性により、社内ルールにもとづく高精度なチャットボットや、専門性の高いデータ分析といったビジネス活用が実現するでしょう。
ただし、RAGシステムで機密性の高い社内情報を扱う場合には、セキュリティ対策が不可欠です。生成AIをターゲットとしたプロンプトインジェクションも増加しており、より一層強固なセキュリティが求められます。
RAGは、単なる「情報を探すAI」から、「知識を育てるAI」へと進化していく将来性も秘めています。RAGの仕組みや精度を高める方法を理解し、生成AI活用を次の段階へと進めてみてください。
OpenStandiaサービス
OpenStandiaは、野村総合研究所(NRI)が提供するオープンソースソフトウェア(OSS)利用の課題を解決する安心のワンストップサービスです。
OSS利用の課題を解決し、企業にもたらすOSSのメリットを感じていただくためのさまざまなサポート&サービスメニューをご用意しています。


