Fluentd情報
Fluentdとは
Fluentd(フルエントディー)は様々なデータの収集を統一できるオープンソースのデータコレクタです。
2011年にTreasure Data(トレジャーデータ)社の古橋 貞之(ふるはし さだゆき)氏によりRubyで開発され、以降はTreasure Data社およびコミュニティベースで開発されています。2016年11月にCloud Native Computing Foundation(CNCF)の6番目のプロジェクトとして承認されました。 その後2019年4月にKubernetes、Prometheusと同様の卒業プロジェクトの一つとしてCNCFに認定されました。
Fluentdは個々のシステム毎に管理されている大量のログファイルを収集、加工し、ストレージに集約、保存を行うツールとして活用されています。 ログに限らず各種データをNoSQLデータベース(MongoDB)やクラウドストレージ(Amazon S3)など様々な媒体に出力できるのも大きな魅力です。 また、Elasticsearch(エラスティックサーチ)、Kibana(キバナ)と連携し、ログの可視化を実現する仕組みとしても注目されています。
近年ではビッグデータ、仮想化やクラウド化の進展に伴い、ログが多様化・肥大化する傾向にあります。 こうした煩雑なログ管理の効率化として大規模Webサービスやビッグデータ基盤においてFluentdが採用される事例が増加してきています。
Fluentdは大きく分けてinput(インプット)、buffer(バッファ)、output(アウトプット)の3つの機能から構成されています。プラグインアーキテクチャを採用しており、プラグインが豊富に用意されているため、多様な組み合わせにより要件に合ったログ管理の実現が期待できます。また、用途に応じたプラグイン開発、拡張を自由に行うことができます。
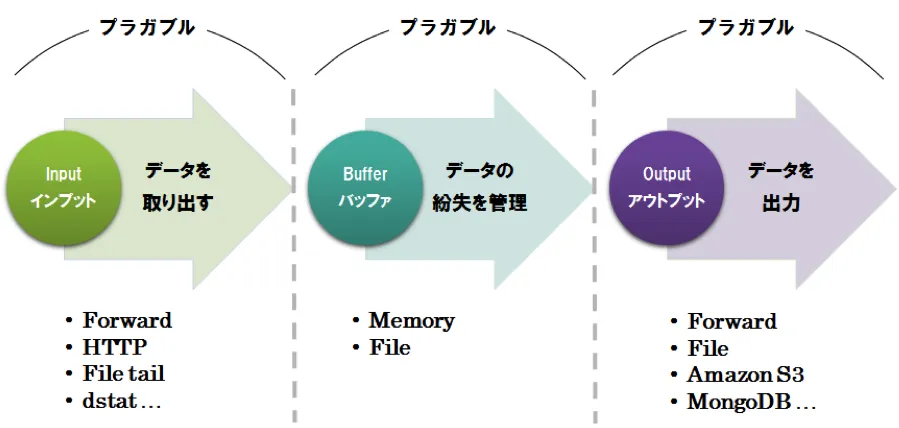
Input(インプット)
各種データソースから必要なデータを収集する
例) 転送データの取り込み、HTTP POSTでの取り込み、イベントログの取り込みなど
Buffer(バッファ)
障害などによるデータの紛失を管理
例) オンメモリ、ファイルによるデータ管理、データの再送など
Output(アウトプット)
各種データ保存先へ出力する
例) ファイル出力、データ転送、データベースへの書き込みなど
FluentdはRuby Gemとして提供されるとともに、td-agentという主要なディストリビュータ向けのパッケージも配布されていました。td-agentは開発元であるTreasure Data社が安定版としてRedHat(rpm)やDebian(deb)、MacOS(dmg)などを提供するもので、いくつかのプラグインも同梱されていました。しかし、td-agentは2023年12月31日にEOLとなり、現在では後継となるFluent Packageへの移行が推奨されています。Fluent Packageはより最新の環境に対応し、継続的なアップデートが提供される予定です。
主な機能
主な機能は以下のとおりです。
|
機能 |
詳細 |
|---|---|
|
ログ転送機能 |
収集したデータを別のサーバへ転送可能。冗長化やアクティブ/スタンバイなどの構成が実現できる。 |
|
バッファリング機能 |
データを欠損することなく管理が可能。オンメモリとファイルの2種類から選択して利用できる。 |
|
フィルタ機能 ※1 |
データの加工や正規表現によるフィルタリングができる。 |
|
プラグイン機能 |
公開されているプラグインは500種類以上あり、様々な要件に応じた機能を選択できる。 |
※1 v0.12以降から提供。
主な特徴
主な特徴は以下のとおりです。
|
マルチプラット |
Rubyの動作環境が揃えば、Linux、MacOS、Windows、UNIXなどさまざまなOSで対応可能。 |
|---|---|
|
柔軟な拡張 |
プラガブルな構成であるため、各機能を独自のプラグインとして自由に開発・拡張ができる。 |
|
高信頼性 |
収集したデータを一時的にバッファに蓄積できる機構を持っているため、障害時のログの再送制御に強く、ログの欠損を防ぐことが可能。 |
|
データをJSON形式で扱える |
収集したログの形式をJSON形式に変換するため、データを構造的に把握でき、後のデータ変換が容易にできる。 |
|
導入・運用が容易 |
ドキュメントが充実しており比較的容易にインストールや機能を拡張できる。基本設定も非常に直観的で容易である。 |
|
豊富な導入実績 |
クラウド環境における大規模システムの運用で多数の採用実績がある。 |
メリット・デメリット
メリット・必要性
- 多様なデータソースと出力先への対応:
標準で様々な形式のログやデータを収集し、主要なデータベース、クラウドストレージ、分析プラットフォームなどと容易に連携できます。
- 柔軟なデータ処理:
収集したデータの加工やフィルタリングなど、柔軟なデータ処理が可能です。
- 高い信頼性:
一時的なネットワーク障害や出力先のシステム負荷が高い場合でもデータを失うことなく安全に転送できます。オンメモリとファイルベースのバッファリングを選択でき、データの重要度やシステムの特性に合わせて設定できます。再送機能も備わっており、データ転送の信頼性を高めます。
- 構造化されたデータ処理:
収集したログをJSON形式のイベントとして内部的に扱うため、データの構造化が容易になり、後の処理や分析が効率的に行えます。parserプラグインを利用することで様々な非構造化データも構造化データに変換できます。
- 高い拡張性:
プラグインアーキテクチャを採用しており、必要に応じて独自のインプット、アウトプット、フィルタなどのプラグインを開発・追加できます。活発なコミュニティによって多数のプラグインが公開されており、様々な要件に対応できます。
- クラウドネイティブな環境への親和性:
CNCFの卒業プロジェクトであり、Kubernetesなどのコンテナ環境との連携が容易です。大規模な分散環境でのログ収集・管理に適しています。
- オープンソースであること:
無償で利用でき、ライセンス費用がかかりません。活発なコミュニティによるサポートや情報共有が期待できます。ソースコードが公開されているため透明性が高く、必要に応じてカスタマイズも可能です。
デメリット・注意点・課題
- 学習コスト:
設定ファイルの記述方式やプラグインの利用方法など、ある程度の学習コストが必要となる場合があります。特に複雑なルーティングやフィルタリング設定を行う場合は設定ファイルの理解や正規表現の知識などが求められます。
- リソース消費:
Rubyで動作するためC/C++で記述されたsyslogdやNXlogと比較するとややリソース(CPU、メモリ)を消費する傾向があります。ただし、軽量版のFluent Bitも存在し、リソースが限られた環境での利用に適しています。
- 設定の複雑さ:
柔軟性が高い反面、複雑なデータ処理やルーティング設定を行う場合、設定ファイルが煩雑になることがあります。適切な設定を行うためには各プラグインの動作やパラメータを理解する必要があります。
- Rubyの知識:
独自のプラグインを開発する場合や高度なカスタマイズを行う場合には、Rubyの知識が必要となります。
- パフォーマンスチューニングの必要性:
大量のログを処理する大規模環境では、適切なバッファサイズ、スレッド数などのパラメータ調整やFluent Bitとの連携など、パフォーマンスチューニングが必要となる場合があります。
類似プロダクト
OSSではsyslogd、NXlog(Community Edition)、Logstashが同様の機能を提供しています。これらの4つを様々な観点で比較すると、以下のようになります。
なお、Fluentdには同様の機能でかつ軽量化・高速化されたFluent BitというOSSもあります。Fluent BitはC言語で実装されており、IoTデバイスやコンテナ環境向けに利用されることが想定されています。Fluent Bitに関してはこちらのページを参照してください。
|
特徴 |
Fluentd |
syslogd |
NXlog (Community Edition) |
Logstash |
|---|---|---|---|---|
|
開発言語 |
Ruby |
C |
C/C++ |
Java |
|
プラットフォーム |
Linux、Windows、macOS |
ほぼ全てのUNIX系OS |
Windows (強み)、Linux、macOS |
ほぼ全てのOS (JVMが動作する環境) |
|
主な用途 |
ログ収集、加工、転送、統合データコレクタ |
システムログ収集の標準 |
Windowsイベントログ収集、汎用ログ収集 |
ログ収集、加工、転送、分析パイプライン構築 |
|
データ形式 |
JSON (柔軟なParserによる多様な形式に対応) |
主にテキスト形式 |
テキスト、イベントログ (構造化データ対応) |
ほぼ全ての形式 (JSONが一般的) |
|
フィタルリング・加工 |
柔軟 (正規表現、Record Transformerなど) |
限定的 |
比較的豊富 (特にWindowsイベントログ) |
非常に強力 (Grok、Mutateなど多様なプラグイン) |
|
出力先 |
Elasticsearch、ファイル、各種DB、クラウドストレージなど |
ファイル、ローカルsyslog、リモートsyslog |
ファイル、TCP/UDP、各種データベースなど |
Elasticsearch、ファイル、各種DB、クラウドストレージなど |
|
バッファリング |
標準搭載 (メモリ、ファイルベース選択可能) |
一般的に無し |
標準機能としてサポート (ファイルベースなど) |
Redisなどを利用した永続キューイング推奨 |
|
プラグイン |
非常に豊富 (500種類以上) |
拡張性限定的 |
比較的豊富 |
非常に豊富 |
|
リソース消費 |
比較的少ない |
非常に少ない |
比較的少ない |
比較的多い (JVM) |
|
信頼性 |
バッファリング、再送機能あり |
シンプル |
バッファリングにより向上 |
設定による (永続キューイングで向上) |
|
学習コスト |
比較的高い (設定ファイルの記述方式など) |
低い |
比較的低い |
比較的高い |
|
コミュニティ |
非常に活発 |
標準的な機能 |
そこそこ活発 |
非常に活発 |
|
クラウドネイティブ |
非常に親和性が高い (CNCF卒業プロジェクト) |
限定的 |
比較的対応 |
コンテナ化可能 |
|
その他 |
軽量、柔軟、統合的なデータ収集基盤 |
シンプルで軽量 |
Windows環境に強み |
ELKスタックの中核 |
Fluentdのライセンス
FluentdはApacheソフトウェア財団 (ASF) によって規定されたApache License Version 2.0を採用しており、著作権の表示などの条件に従うことで、商用利用、修正、再頒布などが自由に行えます。
参考情報
オープンソース年間サポートサービス
OpenStandiaではOSSを安心してご利用いただけるように、オープンソース年間サポートサービスをご提供しております。
サポートしているOSSは下記ページをご参照ください。
関連OSS
-

Logstash
ログスタッシュ。Elastic社により開発された、データ収集ツールです。
-

Kibana
キバナ。Elasticsearchのデータ可視化や、”Elastic Stack”のプロダクト群(Elasticsearch、Logstash、Kibana、Beats)の制御のために利用されるフロントエンドツールです。
-
 サポート対象
サポート対象Elasticsearch
エラスティックサーチ。Elastic社が開発するオープンソースの全文検索エンジンです。