
最新動向
2018.6.26 MongoDB World 2018開催、MongoDB 4.0リリース
2018/6/26-27 ニューヨークにてMongoDB World 2018が開催され、MongoDB4.0を初めとして多くの新製品・新機能が発表されました。
-
MongoDB 4.0
冒頭のキーノートにてGAリリースが発表されました。
- マルチドキュメントトランザクション
これまでMongoDBは単一ドキュメント単位での整合性をサポートするのみでしたが4.0では「start_transaction」から「commit_transaction」までの複数のドキュメントに対する操作をトランザクションとして扱えるようになりました。
ただし4.0では、レプリカセット構成時のみのサポートとなり、シャードクラスタ構成でのサポートは次期4.2を予定しています。
新たなRead Concernとして"snapshot"が導入されるなど、同時実行制御には従来以上に考慮が必要と考えられます。
MongoDB Transaction紹介ページ https://www.mongodb.com/transactions - その他、aggregation pipelineやセキュリティの強化が含まれます。
また、MMAPv1ストレージエンジンは非推奨となりました。
- マルチドキュメントトランザクション
-
MongoDB Atlas
Global Clustersが発表されました。またGCPでのFree Tierもアナウンスされました。
-
MongoDB Stitch
モバイルBackend as a Serviceで、昨年MongoDB World 2017で発表され、ベータ公開されていたものが今回GAリリースとなりました。
Triggerなど複数の機能が強化されました。 -
MongoDB Charts
MongoDBのデータ可視化ツール。Beta版としてリリースされました。
0.9.0(beta)はDockerイメージとして公開されています。 -
MongoDB Mobile
スマホ上で動くMongoDB、MongoDB Mobileが発表されました。
ベータの登録を受け付けています。
なぜMongoDBなのか?「選ばれる理由」
MongoDBは、RDBMSの不得意領域をカバーする新しいアーキテクチャのDBです。
-
スキーマレスデータの格納
RDBMSでは取り扱いが困難なスキーマレスデータの取り扱いが得意
-
ビックデータ格納
スケールアウトしやすいため、低コストで高スループットを実現
-
開発の容易性
- インストール・設定・管理が容易
- RDBMSと類似した機能群を持ち、RDBMS技術者が理解しやすい
- 開発を進めながらデータ構造を変更しやすい
RDBMSがビックデータやスキーマレスデータに適さない理由
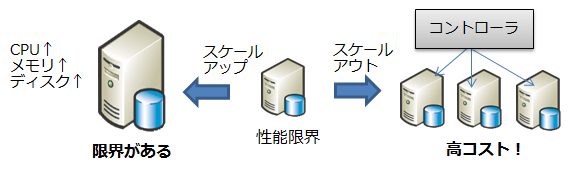
RDBMSではビックデータ処理が高コスト
- 近年のモバイル・ソーシャル対応や IOT(Internet of Things)対応のために、DBに対するアクセス量やデータ量が増加し、RDBMSのスケールアップでは処理の限界を迎えることが多くなってきています。
- 一方で、RDBMSをスケールアウト(水平分散)させるのは困難で高コストになる傾向にあります。
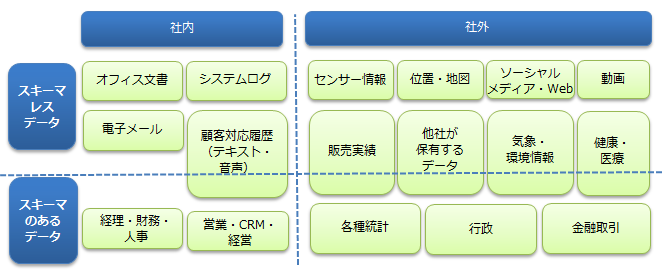
RDBMSではスキーマレスデータの扱いが困難
近年、生成されるデータの80%以上がスキーマレスデータであるといわれています。
スキーマ定義が必須であるRDBMSでは、複雑な階層構造のデータ、データ構造の追加・変更が頻繁に発生するようなスキーマレスデータの格納や取り扱いが難しいと言えます。
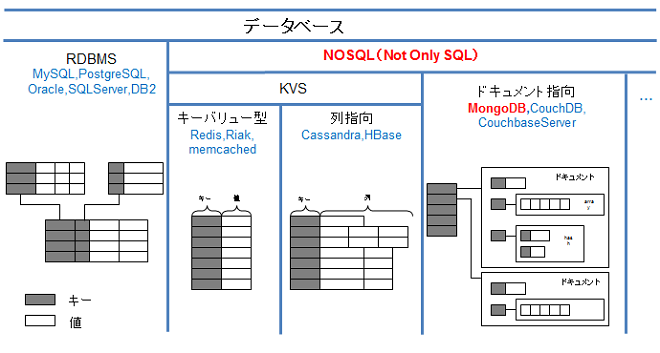
ビックデータ処理、スキーマレスデータ処理が得意なNoSQL
RDBMSの不得意領域をカバーする、NoSQL(Not Only SQL)という新しい考え方のDBが登場
代表的なNoSQL
- MongoDB
- Couchbase
- HBase
- Redis
- membase
- riak
- Apache Cassandra
- Neo4j
NoSQLの特徴
- コストの安いIAサーバや仮想マシンを多く並べて、スケールアウトして処理することにより、低コストで高スループットを実現可能
- スキーマレスデータを取り扱いできる
- 一般的にトランザクションや、データの整合性を取る機能は弱い傾向にある(そのため、用途によってRDBMSとNoSQLを使い分けることが重要)
| 名称 | 水平分散 | スキーマレスデータ | トランザクション | データの整合性 |
|---|---|---|---|---|
| RDBMS | △ | × | ◎ | ◎ |
| NoSQL | ◎ | ◎ | △ | △ |
MongoDBはドキュメント指向データベース
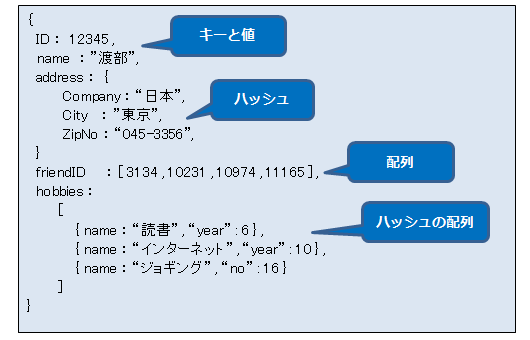
■ドキュメント指向データベースとは
データを階層構造のドキュメント(≒JSON)で扱う
■JSONとは
- ハッシュと配列をネストして使うことができる
- XMLよりシンプルに表現できる
- 読みやすく直観的
■JSONの例
MongoDBの特徴
リッチなデータ
- KVSと比較して、ドキュメント(JSON)はリッチなデータ構造であり、複雑なデータを扱いやすい
柔軟なクエリ
- 動的なクエリ SQLライクなクエリで扱いやすい
例)コレクションpersonに、“name”が“watanabe”で、“age”が30のドキュメントを3つだけ取得したい
- RDBMSと同様に、動的にクエリを作成可能で事前に定義が不要
- 単純な条件検索だけでなく、集計等の高度なクエリも利用可能
RDBMSと同等な、多様なインデックス
- セカンダリインデックス:主キー以外でインデックスを作成可能
- 複合キーインデックス:複数のキーでインデックスを作成可能
- マルチキーインデックス:配列の要素に対してインデックス作成可能
水平分散
- 水平分散(シャーディング)が実現しやすい
キーによってデータをノードに分散することが可能で、ノードを動的に追加し、データを自動バランシングする機能もある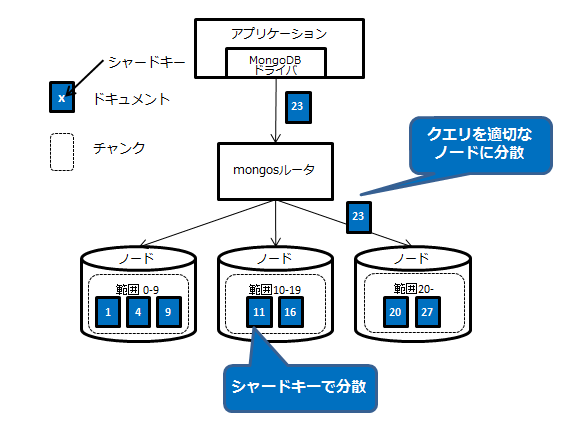
レプリケーション
- 複製(レプリケーション)が容易
- 簡単なコマンドで、マスタースレーブ型のレプリケーションを構築可能
- シャーディングと組み合わせることも可能
- MongoDBドライバが自動的に書き込み先を切り替えるため、仮想IPなどを用意しなくてもフェイルオーバが可能(≒クラスタソフトウェアが不要)
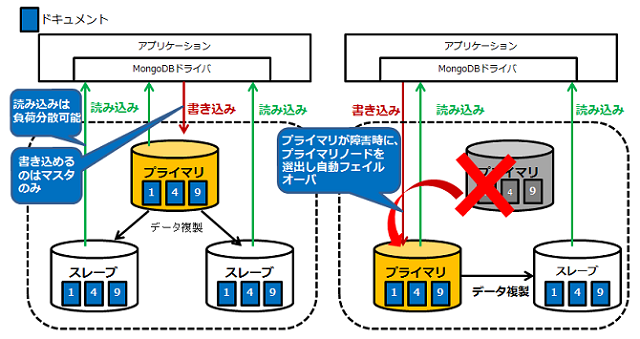
- レプリケーションとシャーディングを組み合わせて、負荷分散と冗長化を両立
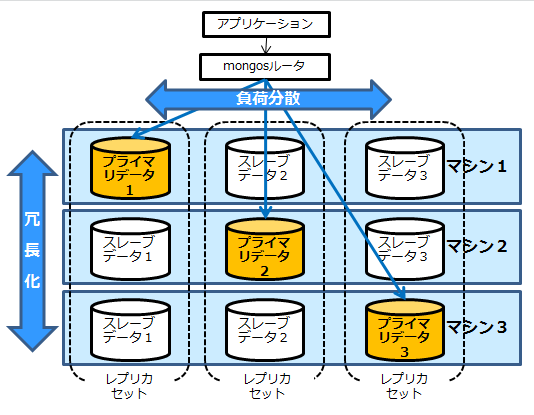
スキーマレス
- スキーマレスデータを取り扱える
- テーブル定義など無しに、すぐにデータをCRUDできる
利用しやすい
- インストールが非常に容易
- OS毎にバイナリがあるため、ライブラリの追加インストールが不要
- 起動までわずか 3ステップ
- OS毎のバイナリをダウンロード
- データディレクトリを作成
- 起動
- RDBMSを使っていた人が使いやすいように作られている
- データベース>テーブル(コレクション)>ドキュメント というデータ構造
- SQLとMongoクエリ言語の大部分はマッピングが可能
- インデックスもSQLと同様の宣言が可能
- 豊富なドキュメント・ノウハウ
- 英語ではあるが、他のNoSQLに比べて公式ドキュメントは豊富
- 多くの人が使っているため、ノウハウが豊富。日本語のノウハウも多い
多機能
- 他にも数多くの便利な機能が豊富
分類 機能 説明 ユースケース 機能 GridFS
大容量ファイル(16MB以上)を扱うことができる
大容量ファイルをドキュメントに分割して格納し、アプリケーションには等価的なAPIを提供大容量ファイルの管理
地理空間インデックス
2Dや3Dのデータを格納し、それに対して交点や近傍などの検索をかけることができる
アプリでの作りこみが不要地理アプリのデータベース
キャップ付き・期限付きコレクション
サイズや期間を指定したコレクションを作り、自動的に古いドキュメントを引き落とせる
ログ保管
集計機能
SQLグループ関数のように集計できる
また、map/reduceによる集計も可能データ集計
耐障害性 ジャーナリング
単一ドキュメントに対して、書き込みの一貫性が保持できる
突然の電源停止等に対応したい
運用性 各種機能コマンド
さまざまなサーバの統計情報を取得するツールや、JSON形式で出力するコマンドがある
運用監視ツールとの対応
障害対応効率化MMS(MongoDB Management Service)
MongoDBの監視やアラート、自動バックアップ、ポイントインタイムリカバリ等ができるサービス
運用監視の仕組みを簡単に作りたい
MongoDBを使う上での注意点
トランザクションが無い
- MongoDBが複数のドキュメントを一貫性をもって更新することができない
- ミッションクリティカルで複数のテーブルの更新を保証しなければならないようなシステムでは、利用してはならない
- ただしバージョン4.0にて複数ドキュメントに対するトランザクション機能が追加されました
外部キー・結合が無い
- 他のドキュメントへの参照はアプリケーションで実装する必要がある
- 当然ながら、外部キー制約もないため、テーブル間の整合性が重要なシステムには向いていない
- 複数のドキュメントの内容を結合して取得することはできない
スキーマが無い
- 格納されているデータのキー名やデータ型が分からない
- データ登録の際に不具合があってもエラーが発生しない
- 設計書を厳格に管理しないと、格納データの内容が分からなくなり、保守性の低下を招く恐れがある
NoSQLならば、MongoDBから
世界には数多くのNoSQLがあります。いずれも独自のノウハウが必要となり、習得期間とコストを要します。
その中で、OpenStandiaでは「MongoDB」を推奨しています。
NoSQLの中では多機能で、敷居が低い
- 他のNoSQLと比較して機能が豊富である
- RDBMSと類似した機能群を持ち、RDBMS技術者が理解しやすい
- 導入が非常に容易で、すぐに開発を始められる
- 開発を進めながらデータ構造を変更しやすく、生産性が高い
NoSQLの標準になりつつある
- 最も人気のあるNoSQLであり、米国ではNoSQLの標準になりつつある。
- 開発元のMongoDB,Inc. は、2013年10月に150M$(約150億円)の投資を受け、NoSQL企業の中でも企業活動が活発である。
- [参考]米MongoDB、1億5000万ドルの資金調達「Oracleに追いつく成熟度を目指す」
- [参考]solid IT社の提供する「DB-Engines Ranking」で、MongoDBがNoSQL部門で人気No.1
- [参考]ZDNet Japan DB人気ランキング--NoSQLなど注目されるも従来型RDBMSが支配的
- [参考]MongoDB社サイト Google Search、LinkedIn Job SkillsなどのMongoDB人気度を紹介
豊富な導入実績がある
- 600社以上の導入実績がある。
- IT企業のほか、金融や保険業界での活用事例も出てきている。
- MetLife
- SAP
- eBay
- McAfee
- Cisco など多数
[参考]MongoDB社サイト ビッグデータ導入事例
[参考]MongoDB社サイト Internet of Things導入事例
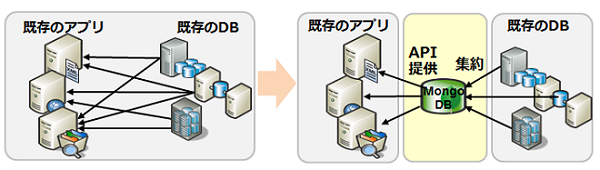
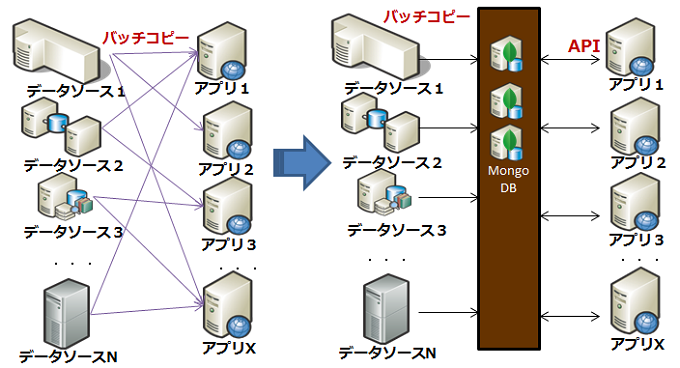
利用シーン(1) スキーマレスデータ処理
データハブ
既存のレガシーデータの集約基盤として利用
- スキーマレスであるため、様々なスキーマのRDBMSからデータを集約することが容易
集計したデータは、性能要件の高いモバイルアプリ等に提供
事例:MetLife
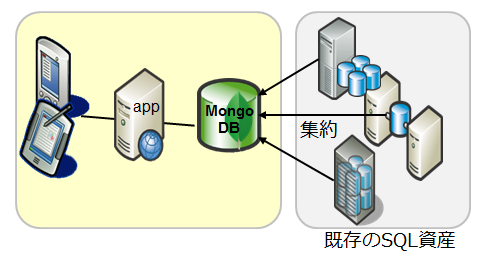
コストのかかる商用製品の代わりに、MongoDBをデータハブとして利用
事例:グローバル信託銀行 X社
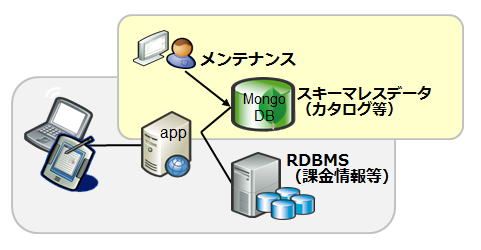
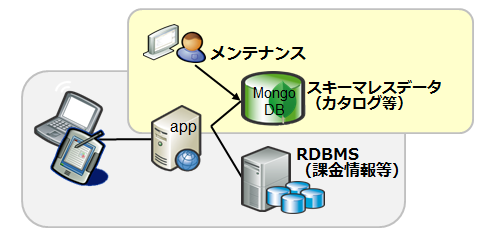
RDBMSとMongoDBのハイブリッド
スキーマレスが向いているデータのみをMongoDBで処理
- 既存のシステムのスキーマレスデータをMongoDBに切り出すことにより、スキーマ変更の負荷軽減や、性能向上が可能
- 特に商品カタログ等の多様なフォーマットで更新頻度が多いデータを、MongoDBで扱うことが多い
事例:野村総合研究所
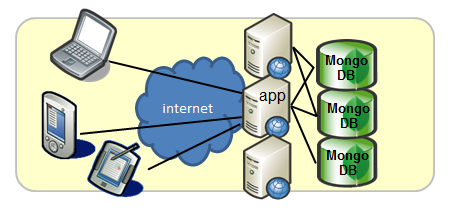
利用シーン(2) ビックデータ処理
MongoDBを単体で使う
大量トラフィックのWebシステム/オンラインゲームでメインDBとして
- ユーザの増加に合わせて横に並べればよい
- リッチなデータ構造を扱えるので、複雑なアプリケーションにも対応
事例:McAfee
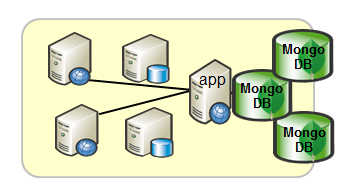
ログ格納
- ログデータはスキーマレスであり、整合性について厳密な要件がないため最適
- レプリケーションすることでデータロストの懸念もない
事例:野村総合研究所
既存データから統計情報を取得して、経営判断に役立てる
戦略的アプリのデータベースとして利用
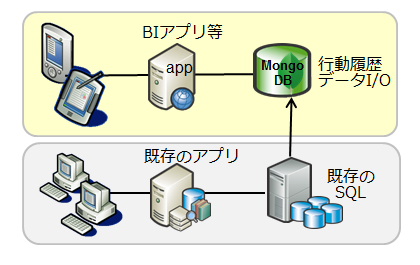
利用シーン(3) その他の使い方
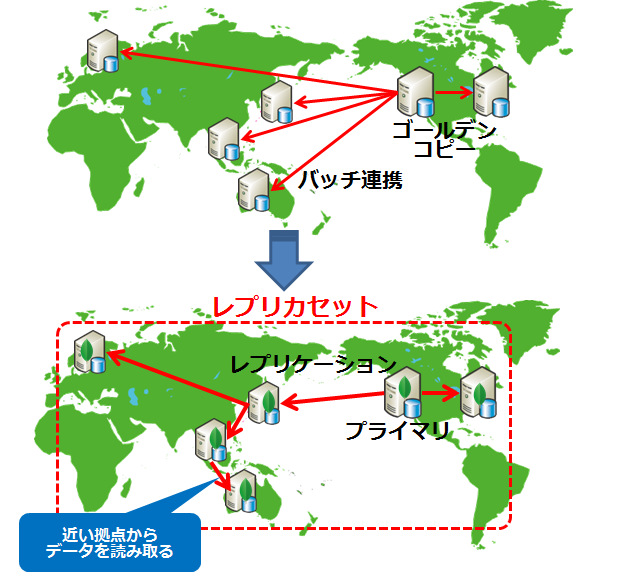
高機能なレプリケーションをフル活用
従来のバッチ連携をMongoDBのレプリケーションに置き換え
- リアルタイムに同期するため、連携時間を短縮
- 近い拠点からデータを取得するため、通信効率が良い
事例:グローバル信託銀行 X社
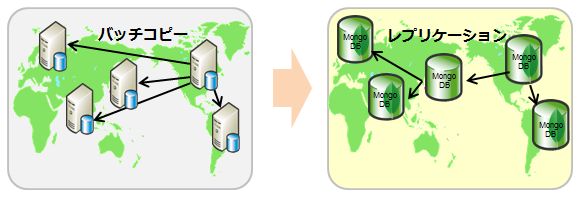
アジャイル開発で利用
頻繁にスキーマ変更が発生するアジャイル開発ではスキーマレスが生産性アップの秘訣
- テーブル定義の管理が不要
- すぐに使い始められる
- JSONでのデータ出し入れが可能で、ライトウェイトなスクリプト言語との相性が良い
導入事例(1) OracleRACからMongoDBへ移行
データハブ&検索基盤&分析基盤
[国内][不動産] 不動産情報物件検索サイト
Oracle RACからMongoDBへ移行、性能向上とコスト削減を実現
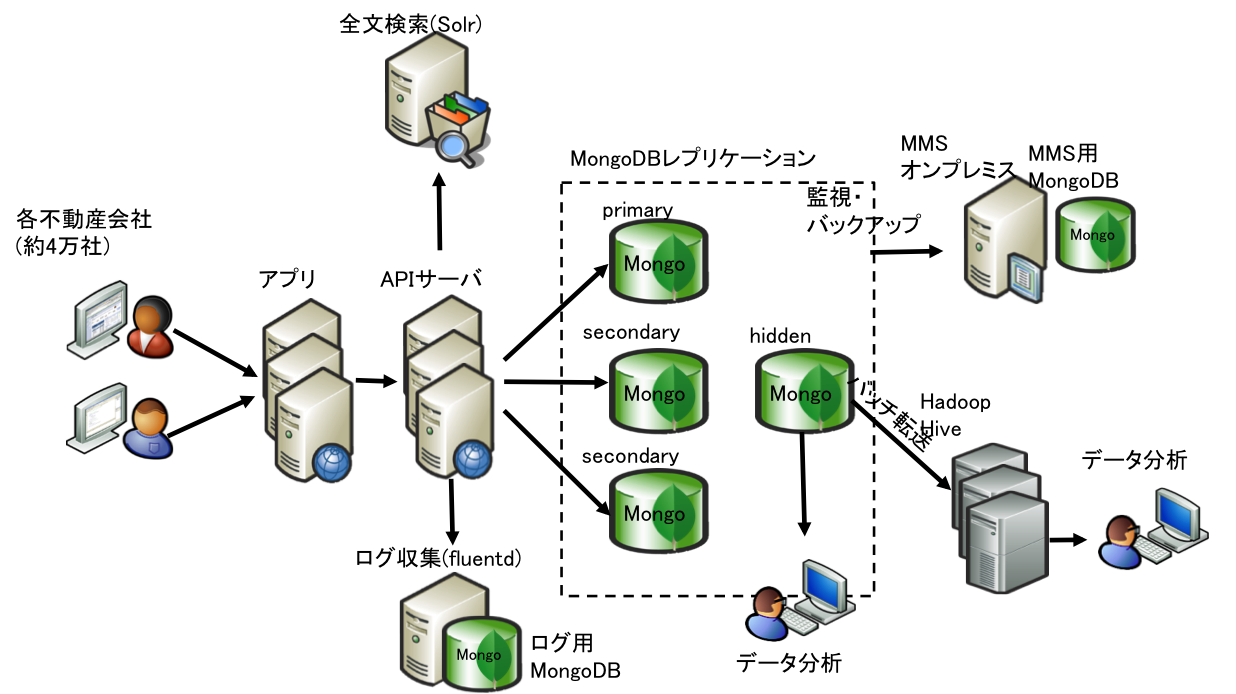
- 約4万社の不動産会社が使っている物件検索サイト
- 検索はSolrで行い、実態をMongoDBに格納する
- APサーバに来る参照リクエスト量は毎分5000リクエスト。
- 更新は毎日20万~30万ドキュメント
- 物件データは700万ドキュメントで300GByte
- オンラインリクエストを受け付けないhiddenレプリケーションノードを用意し、分析に用いる。
- 一日に一回バッチでHadoopクラスタに連携し、Hiveにてデータ分析を行う。用途として、MongoDBではインデックスがかからないような集計や、コレクションをまたいだ集計を行う。
- MongoDBの監視およびバックアップにオンプレミス版MMS(MongoDB Management Service)を利用。
- サーバのログはfluentdにて収集しMongoDBに格納。
| 課題 |
|
|---|---|
| 選定理由 |
|
| 結果 |
|
導入事例(2) スキーマレスデータ処理
データハブ
[海外][保険] MetLife
70以上の既存RDBMSに拡散している顧客情報をMongoDBで統合
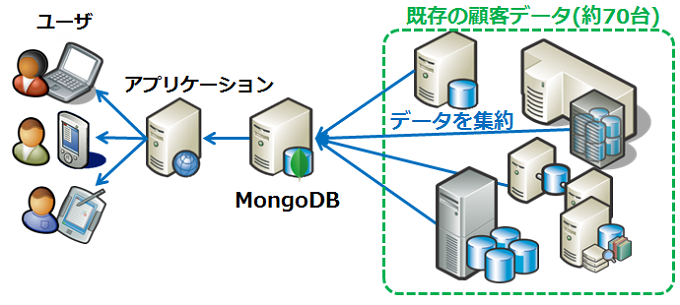
※出典:MongoDB,Inc.
| 課題 | 選定理由・解決策 | 結果 |
|---|---|---|
|
70台以上ものDBで個別に管理している既存顧客データを統合したい |
|
|
|
モバイルで利用したいため、端末の増加に合わせたDBを選定したい |
|
|
[海外][金融]グローバル信託銀行 X社
企業内でのデータアクセスを統合するために、データハブとして利用
| 課題 | 選定理由・解決策 | 結果 |
|---|---|---|
|
システム間で無数に存在するデータの複製を正規化したい |
必要な時だけデータを正規化するため、MongoDBの動的なスキーマを利用 |
一カ所からバッチ、もしくはRESTでデータアクセスが可能になった |
|
一つのシステムでの変更が、複数のグループに影響してしまうため、影響範囲を限定し、レスポンスを改善したい |
一つの論理DBで全てのデータを管理・運用できるため、MongoDBを選定 |
顧客向けポータルサイトのレスポンスタイムが90%改善した |
|
EDWシステムのレスポンスを改善したい |
スケールアウトによりデータを容易に追加するよう、MongoDBのシャーディングを利用 |
EDWのシステムレスポンスタイムを大幅に改善した |
|
頻繁にアクセスするデータを集中的に管理したい |
企業内でのデータアクセスを統合するために、データハブとしてMongoDBを利用 |
データを集中的に管理したことで、開発期間が短縮でき、データソースのエンハンスも容易になった |
RDBMSとMongoDBのハイブリッド
[国内][SIer] 野村総合研究所
カード会社向けシステムで、アプリケーションの一部のスキーマレスデータ処理にMongoDBを利用
| 課題 | 選定理由・解決策 | 結果 |
|---|---|---|
|
スキーマレスデータに対してSQLと同等のクエリをかけたい |
他のNoSQL技術と比較しても、利用実績が多く、流行しているため技術者も多かった |
スキーマデータはRDBMS、スキーマレスデータはMongoDBという使い分けがうまくできた |
|
NoSQLに不慣れな開発者にも簡単にクエリをかける |
NoSQLの中では唯一社内のサポート体制が整っていた |
他のDB技術と比較して冗長化の設計工数が飛躍的に少なくすんだ |
|
上記の要件を満たすDBを探す |
従来のRDBMSでは上記の2つの要件を満たせなかったが、これらの要件を満たすMongoDBを選定 |
開発者が簡単にスキーマレスデータを操作でき、開発生産性を高く保つことができた |
導入事例(3) ビックデータ処理
MongoDBを単体で使う
[海外][セキュリティ] McAfee
セキュリティサービスのビッグデータ解析にMongoDBを利用
※出典:MongoDB,Inc.
| 課題 | 選定理由・解決策 | 結果 |
|---|---|---|
|
スケーラビリティと機能がともに十分なDBを探す |
MongoDBの自動シャーディングを利用 |
スケーラビリティを実現し、レイテンシーを1/3に削減できた |
|
複雑なクエリに対応しているDBを探す(Hbase/Hadoopでは複雑なクエリに対応できない) |
MongoDBは動的に柔軟なクエリが書け、新しい分析結果を追加する場合の開発が簡単である |
動的スキーマの変更が可能になり、開発者の生産性が大幅に向上した |
|
スケーラビリティがあるインデックスを探す(Luceneではスケーラビリティに問題がある) |
MongoDBの地理空間インデックスの利用する |
MongoDBの地理空間インデックスの利用により、地理的な観点でのデータ分析が容易になった |
導入事例(4) その他の使い方
高機能なレプリケーションをフル活用
[海外][金融]グローバル信託銀行 X社
各拠点で迅速にローカルアクセスができるよう、参照データをリアルタイムで分散/配布
| 課題 | 選定理由・解決策 | 結果 |
|---|---|---|
|
最大36時間に及ぶバッチ処理によるデータ配布の遅れを改善したい |
データ配信がリアルタイムで、かつ拠点ではローカルデータを読むことが可能なMongoDBの自動レプリケーションを利用 |
データ遅延の違反金$40Mを5年間の間に節約することができた |
|
同じデータのグローバル配信に複数課金されるSLA未達成による規制違反(罰金)をなくしたい |
近い拠点から読み取ることが可能なMongoDBの柔軟なレプリケーションを利用 |
レプリケーションの活用で統一したグローバルデータサービスに移行できた |
|
同じデータを保有する20カ所の分散システムを管理する必要がある |
直観的なデータモデルであるJSONを利用 |
理解しやすく変更が容易であったため、高い生産性で分散システムの管理を実現できた |
機能一覧
| 機能 | MongoDBでの対応状況 | ||
|---|---|---|---|
| 機能性 | 問合せ |
条件検索 |
○可能 |
DISTINCT |
○可能 |
||
LIKE検索 |
△英語のみ可能(日本語は不可) |
||
ROWID、ROWNUM、ROW_NUMBER |
△結果行数指定の使い方は可能 |
||
グループ集計 |
○可能 |
||
ソート |
○可能 |
||
正規表現 |
○可能 |
||
WITH句/副問い合わせ |
△パイプラインで一部代替可能 |
||
TRUNCATE |
○可能 |
||
再帰クエリ |
×不可 |
||
ユニオン/結合 |
×不可 |
||
全文検索 |
△英語のみ可能(日本語は不可) |
||
トランザクション管理 |
○可能(4.0から。レプリカセット環境のみ。) |
||
排他制御 |
×不可 |
||
制約/整合性機能 |
×不可 |
||
インデックス |
オンライン追加・削除 |
○可能 |
|
セカンダリインデックス |
○可能 |
||
複合インデックス |
○可能 |
||
マルチキーインデックス |
○可能 |
||
データ |
基本データ型 |
○可能 |
|
大容量ファイル格納 |
△16M以上のファイルは別DB(GridFS)での管理 |
||
マルチメディア |
△大容量ファイルの分散管理が可能 |
||
空間データ |
◎座標系データの検索が可能 |
||
OLAP |
×不可 |
||
操作 |
管理ツール(CUI) |
○可能 |
|
管理ツール(GUI) |
△基本操作が可能(アドバイザ等はなし) |
||
その他 |
動的SQL |
○可能 |
|
データベーストリガ |
×なし |
||
ジャーナリング |
○ドキュメント単位で一貫性保証 |
||
ストアドプロシージャ/ファンクション |
○可能 javascriptで記述 |
||
一時表 |
△キャップ付きコレクションで保管期間を決められる |
||
シーケンス |
△ストアドプロシージャで処理を代替可能 |
||
| 可用性 | 耐障害性 |
○レプリケーションで冗長構成可能 |
|
復旧容易性(ノード復旧) |
○ノード起動により自動復旧 |
||
データ損失許容時間 |
○クエリごとに制御可能 |
||
| 拡張性 | シャーディングノード追加 |
○オンラインで追加可能 |
|
レプリケーションノード追加 |
○オンラインで追加可能 |
||
メモリ追加 |
○可能 |
||
ディスク追加 |
○可能 |
||
| 運用性 | 統計情報出力 |
○付属のコマンドで可能 |
|
データダンプ・リストア |
○付属のコマンドで可能 |
||
インポート |
○JSONをインポート可能 |
||
監視 |
○MMSで監視可能 |
||
OS監視 |
○MMSとmuninの組み合わせにより可能 |
||
バックアップ |
○MMSにて自動バックアップ、ポイントインタイムリカバリ可能 |
||
バージョンアップ |
○レプリケーションを組んでローリングアップデートすればシステム停止無しで実施可能 |
||
サポート |
○OpenStandiaにてサポート可能 |
||
| 機密性 | アクセス制御 |
○可能 |
|
暗号化 |
○商用版でSSL利用可能 |
||
監査ログ |
○商用版で利用可能 |
||
OpenStandiaサービス
OSS利用の課題を解決し、企業にもたらすOSSのメリットを感じて頂くためのさまざまなサポート&サービスメニューをご用意しています。