生成AIとは?
種類や仕組み、ビジネス活用事例を
わかりやすく解説
2025/11/13
近年、急速に進化している「生成AI」は、AIのなかでも学習データをもとにテキストや画像、プログラムコードなどのコンテンツを自動で生成する人工知能技術です。ChatGPTをはじめとする生成AIは、これまで人間が行ってきた作業を大幅に効率化し、コスト削減や新しいアイデア創出などに貢献しています。しかし、その一方で誤情報の生成や情報漏洩リスクなども存在し、安全かつ効果的に活用するためには生成AIに対する正しい知識が欠かせません。 本記事では、生成AIの基礎知識から業務での具体的な活用事例、さらにOSSとの組み合わせまでを解説します。知っておくべきリスクや対策を網羅的に解説するので、業務に生成AIを安全に取り入れたい方は、ぜひ最後までご覧ください。
目次
生成AIとは?従来のAIとの違いを解説
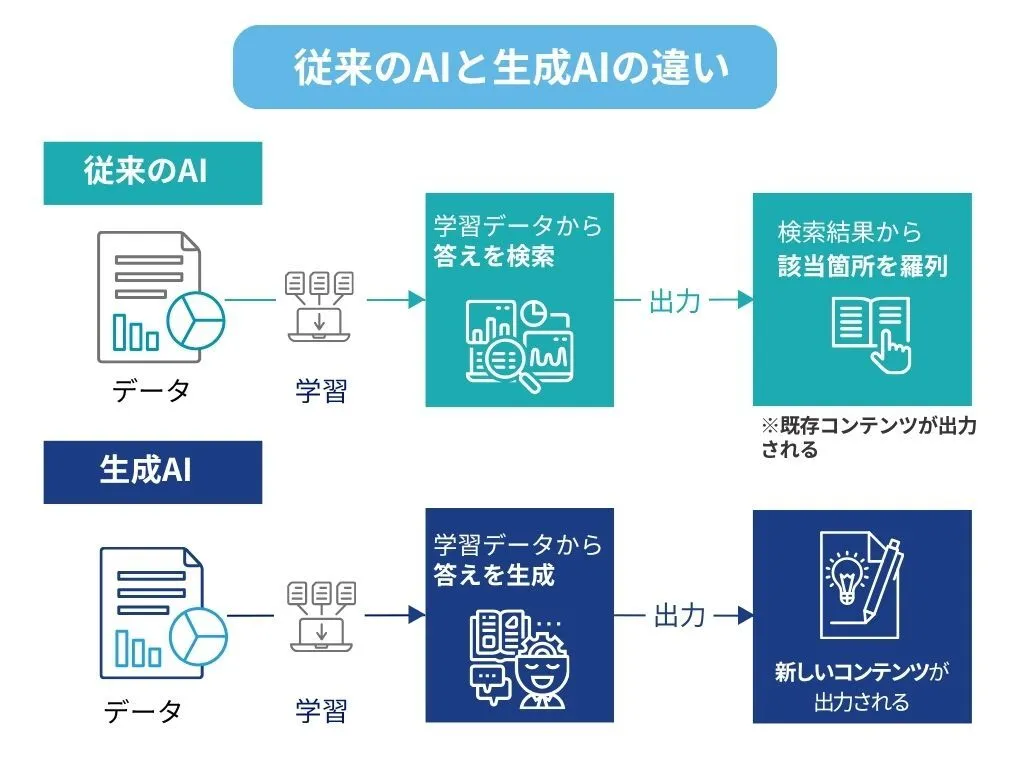
まず、従来のAIと生成AIの違いを解説します。従来のAIは、画像の中の物体を識別したり、過去のデータから結果を予測したりと、主に「判断・分類」に特化していました。これに対し、生成AIは高い汎用性を持っているのが特徴です。学習した知識をもとに、新しい文章や画像、音声、プログラムコードなどを生成することができます。
本記事では、生成AIの仕組みや特徴とあわせて、文章やプログラムコードなど多様な生成タスクに対応できる注目の生成AI技術「大規模言語モデル(LLM)」について、わかりやすく解説します。
生成AIの仕組みと特徴
従来のAIはデータを分析し、分類や予測を行うことが中心でしたが、生成AIは新しいコンテンツを創り出せる点が大きな違いです。そのため、文章作成や画像生成、音声合成など、クリエイティブな作業にも応用でき、多様な分野での活用が急速に広がっています。
生成AIの技術は、線形代数や確率論、情報理論など、数学的な基盤の上に成り立っています。線形代数を使ってデータを効率的に計算し、確率論を用いて「次に生成される可能性が高いもの」を予測することで、コンテンツの生成を実現しているのです。
また、情報理論の考え方もデータの圧縮や効率的なやりとりに活用されており、大量のデータからAIが意味のあるパターンを見つけ出す基盤となっています。
数学的な基礎は普遍的ですが、生成AIのモデルや手法は進化が非常に早く、今後も新しいアーキテクチャや応用分野が登場すると考えられます。
生成AIと大規模言語モデル(LLM)の違い
生成AIは、文章・画像・音声・プログラムコードなど、さまざまな形式のコンテンツを自動で生み出す人工知能の総称です。その中で、大規模言語モデル(LLM)は「特にテキストを扱う生成AI」の一種です。
生成AIには大きく分けて以下の種類があります。
- テキスト生成AI:文章やコードを生成する(例:GPT、Claude、LLaMA)
- 画像生成AI:絵や写真風画像を生成する(例:Stable Diffusion、DALL·E)
- 音声生成AI:人間のような音声を生成する(例:VALL-E、AudioLM)
- その他の生成AI:動画生成、3Dモデリングなど(例:Sora、Luma AI)
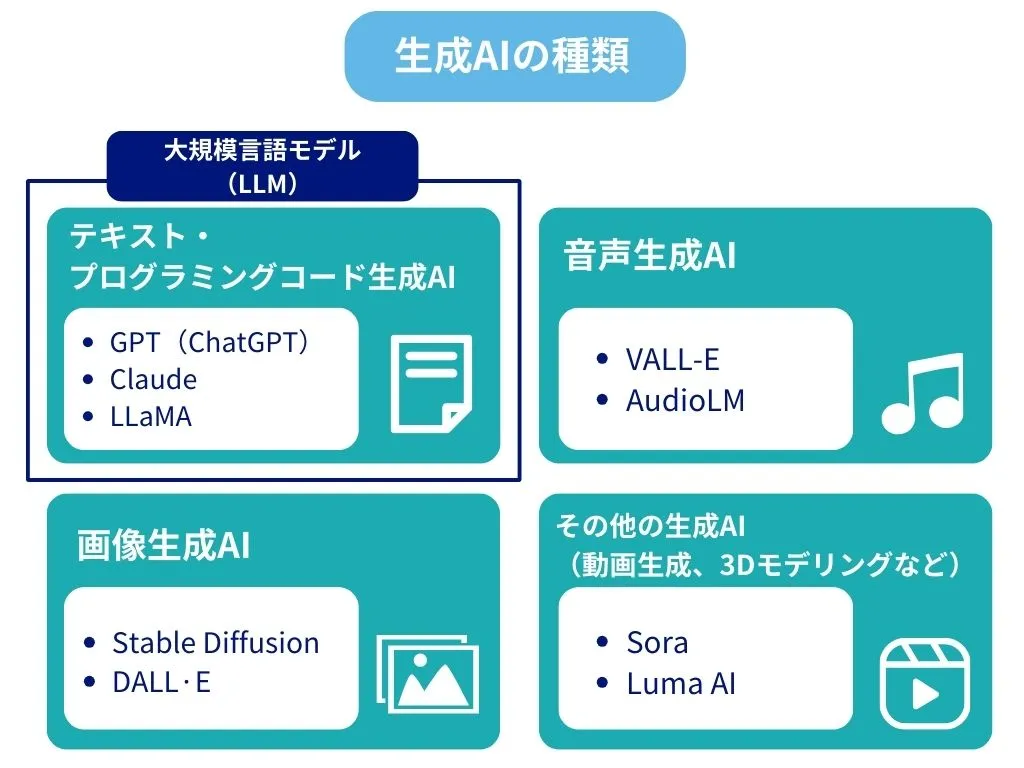
LLMは、このうちテキスト生成AIに属します。LLMは膨大なテキストデータを学習し、数億~数千億のパラメータを持つことで、文脈を深く理解しながら自然で意味のある文章を生成できます。単に文法的に正しい文章を作るだけでなく、単語やフレーズの微妙なニュアンスを捉え、書き手の意図を推測して適切な文章を生み出せるのが特徴です。
生成AIが注目される背景
これまで「AI(Artificial Intelligence、人工知能)」といえば、機械学習や深層学習を活用してデータを分析し、分類や予測を行う技術が主流でした。しかし近年、生成AIといった「新しいコンテンツを生み出すAI」が急速に台頭し、一般利用が広く普及しました。この変化の背景には、「技術的な進歩」と「社会的な要因」が複合的に作用しています。
技術的な要因
- 基盤技術の進化:Transformerアーキテクチャや深層ニューラルネットワークの発展により、大規模で高性能なモデルの構築が可能になったため。
- 学習データの増加:インターネットやIoTの普及により、文章・画像・音声など多様で膨大なデータが利用可能になったため。
- 計算資源の拡大:GPUやTPUなどのハードウェア性能向上により、巨大なモデルの学習・推論が現実的になったため。
社会的な要因
- 使いやすいサービスの登場:ChatGPTのような対話型サービスにより、専門知識がなくても生成AIを体験できる環境が整ったため
- 社会的関心の高まり:生成AIの実用例がメディアやSNSを通じて広く共有され、ビジネスや日常生活への応用期待が急速に拡大したため。
このように、技術と社会の両面から追い風が吹き、生成AIはかつてないスピードで普及と進化を続けています。こうした背景のもと、特にテキスト生成分野で注目を集めているのが大規模言語モデル(LLM)です。次章では、代表的なLLMの種類とそれぞれの特徴について解説します。
LLMの種類と特徴
生成AIの中でもLLMは、モデルの設計思想や学習方式の違いによっていくつかの種類に分けられます。それぞれ異なる特徴と得意分野があり、用途に応じて使い分けます。本章では、Transformerアーキテクチャ(Googleが開発)を基盤とするLLMの代表例として、デコーダー型のGPT、エンコーダー型のBERT、エンコーダー+デコーダー型のT5を取り上げ、それぞれの特徴を解説します。
Transformerとモデル構造
多くのLLMは、Googleが開発したTransformerアーキテクチャを基盤としています。Transformerは、入力を解析するエンコーダーと、解析結果から出力を生成するデコーダーの2つの構造から成ります。モデルによって、このエンコーダーとデコーダーのどちらを重視するか、または両方を組み合わせるかが異なり、それが得意分野の違いにつながっています。
GPT
GPT(Generative Pre-trained Transformer)
- 開発元:OpenAI
- 構造:Transformerのデコーダー部分を強化・活用
- 特徴:一貫性のある自然な文章生成に特化
- 得意分野:
- コンテンツ作成(マーケティングコピー、メール文生成)
- プログラミング支援(コード生成、コード提案)
- 対話システム(チャットボット、カスタマーサポート)
- ポイント:名前の通り「Generative(生成)」に強く、新しいテキストを創り出す能力が高い。
BERT
BERT(Bidirectional Encoder Representations from Transformers)
- 開発元:Google
- 構造:Transformerのエンコーダー部分を活用
- 特徴:文章の文脈理解に特化(文脈を双方向(前後方向)から考慮)
- 得意分野:
- 検索エンジン(検索意図の理解、関連性の高い結果の提示)
- 質問応答(既存文書から正確な答えを抽出)
- テキスト分類(ニュース記事の分類、スパム判別)
- ポイント:生成よりも「理解」が得意。文中の単語の意味を前後の文脈から正確に把握できる。
T5
T5(Text-to-Text Transfer Transformer)
- 開発元:Google
- 構造:Transformerのエンコーダーとデコーダー両方を組み合わせ
- 特徴:文章を読み(理解)、新しい文章を作り出す(生成)といった、多様な言語処理をすべて「テキスト入力→テキスト出力」という同じ流れで実行
- 得意分野:
- 自然言語処理タスク(翻訳、要約、質問応答、テキスト生成、分類)
- 多言語処理(複数言語間での翻訳や理解)
- ポイント:入力と出力をすべて「テキスト→テキスト」に変換するため、幅広いタスクに柔軟に対応可能。
主要LLMの比較(Transformerベース)
| モデル名 | 開発元 | 構造タイプ | 主な特徴 | 得意分野 |
|---|---|---|---|---|
|
GPT(Generative Pre-trained Transformer) |
OpenAI |
デコーダー型 |
一貫性のある自然な文章生成に特化 |
コンテンツ作成、プログラミング支援、対話システム |
|
BERT(Bidirectional Encoder Representations from Transformers) |
|
エンコーダー型 |
双方向の文脈を理解し、文章の意味を正確に把握 |
検索エンジン、質問応答、テキスト分類 |
|
T5(Text-to-Text Transfer Transformer) |
|
エンコーダー+デコーダー型 |
あらゆる言語処理を「テキスト→テキスト」に統一 |
翻訳、要約、質問応答、テキスト生成、分類、多言語処理 |
このように、LLMは構造や設計思想によって得意分野が異なりますが、いずれのモデルも共通して、高度なAI技術を基盤としています。次章では、これらのモデルを支える生成AIの主要技術について解説します。
生成AIに使用されている技術
ここでは、生成AIの主な基礎技術について、基盤理論・構造/学習手法/生成モデル/周辺技術の分類に分けて解説します。
| 分類 | 技術名 | 概要 |
|---|---|---|
| 基盤理論・構造 |
ニューラルネットワーク |
人間の脳の神経細胞(ニューロン)の仕組みを模倣した構造。入力層・隠れ層・出力層で構成され、データの特徴を学習する。 |
|
ディープラーニング(Deep Learning) |
ニューラルネットワークを多層化して表現力を高めた技術。画像・音声・自然言語処理などで高精度を実現。 |
|
|
Transformerアーキテクチャ |
Googleが2017年に発表。入力を解析する「エンコーダー」と出力を生成する「デコーダー」から成り、長い依存関係を効率的に処理可能。 |
|
|
自己注意機構(Self-Attention) |
入力データの中で重要な部分を動的に特定し、重要度を数値化して処理する仕組み。Transformerの中核技術。 |
|
| 学習手法 |
自己教師あり学習(Self-Supervised Learning) |
ラベルなしデータを用いて特徴を学習する手法。マスク化言語モデル(BERTなど)や自己回帰型モデル(GPTなど)が代表例。 |
|
強化学習(Reinforcement Learning) |
行動と報酬を通じて最適な出力を学習。特にRLHF(人間のフィードバックによる強化学習)はChatGPTで重要。 |
|
|
大規模分散学習 |
複数GPU/TPUを用いて膨大なパラメータを持つモデルを並列学習する技術。 |
|
| 生成モデル |
GAN(Generative Adversarial Network) |
生成モデルと識別モデルを競わせて学習し、高品質なデータを生成。主に画像分野で活用。 |
|
VAE(Variational AutoEncoder) |
データを圧縮して特徴を学び、その特徴から新しいデータを生成する生成モデル。 |
|
|
拡散モデル(Diffusion Model) |
データに徐々にノイズを加え、逆にノイズを除去する過程を学習することで、高精細な画像生成を可能にする。 |
|
| 周辺技術 |
LLM(Large Language Model) |
大規模テキストデータで学習した言語モデル。GPT、BERT、T5などが代表例。 |
|
MCPサーバ |
AIと外部ツール・APIを接続する基盤。ファイル操作・データベースアクセス・システムコマンド実行などの操作を特定のAIに依存しないオープンプロトコルで提供する中継サーバ。 |
生成AIは、これらの技術の組み合わせによって成り立っています。
LLMの性能を支える中核的役割を担うのは、Transformerと自己注意機構。一方で、GANや拡散モデルのように、画像や動画の生成に特化したアーキテクチャも存在します。
また、自己教師あり学習や強化学習(特にRLHF)は、モデルをより人間らしく、文脈に沿った出力へと最適化する重要な手法です。
周辺技術としてのMCPサーバは、業務システムや外部APIとの統合を容易にし、生成AIの活用範囲をさらに広げています。
生成AIのトレーニング方法
生成AIが高品質なコンテンツを生成するためには、大量のデータを使って学習する「トレーニング」というプロセスが不可欠です。トレーニングは大きく、事前学習(Pre-training)、ファインチューニング(Fine-tuning)、最適化(アライメント、Alignment)の3段階に分かれます。
トレーニングの流れ
- 事前学習(Pre-training)
・大量のデータセットを使い、自己教師あり学習で一般知識やパターンを学ぶ
・例:次の単語を予測(GPT型)、欠けた単語を予測(BERT型)
・この段階でモデルは言語やデータの基礎構造を獲得する - ファインチューニング(Fine-tuning)
・学習済みモデルに新しい情報を追加し、特定用途に最適化する
・例:医療データで学習した医療特化モデル、企業FAQで学習した社内チャットボット
・少ないデータ量でも高精度を発揮可能(転移学習の応用) - 最適化・アライメント(Alignment)
・モデルを人間の意図や倫理基準に沿わせる工程
・代表手法:RLHF(Reinforcement Learning from Human Feedback)
・人間が出力を評価し、その結果をもとにモデルを改善することで、安全で有用な応答を生成
生成AIのトレーニングを理解する上で押さえておきたい重要用語
| 用語 | 概要 |
|---|---|
| データセット |
生成AIが学習するために使う、整理された情報の集まりのこと。コード生成においては、プログラミング言語のコードがデータセットに該当する。 |
| データ前処理 |
データセットを、AIが学習しやすいように整える作業。不要な情報を取り除いたり、データを標準化したりする。 |
| トレーニングプロセス |
加工されたデータセットをAIに読み込ませ、学習させる一連の手順。トレーニングプロセスを繰り返すにつれ、徐々に正確で自然なコンテンツを生成できるようになる。 |
| 追加学習(ファインチューニング) |
すでに学習済みの生成AIモデルに、新しい情報を追加して再度学習させる方法。過去の学習を維持しつつ、柔軟性を高められる。 |
| 転移学習(トランスファーラーニング) |
すでに学習済みの生成AIモデルを、別の関連するタスクに適用させる方法。少ないデータと計算リソースで、効率よく学習を進められる。 |
トレーニング方法と関連用語を理解しておくことは、生成AIの性能や活用範囲を正しく評価し、目的に応じたモデル選定や運用を行う上で不可欠です。次章では、こうして学習された生成AIの種類と代表的なサービス例について解説します。
生成AIの種類と代表的なサービス例
生成AIは、テキストやプログラムコードだけではなく、画像・動画・音声・音楽など幅広いコンテンツを自動生成できます。
- 文章生成:ChatGPT、Claude、Gemini、Grok
- 画像生成:DALL·E、Midjourney、Stable Diffusion
- 動画生成:Sora、Runway Gen、Pika、Grok Imagine
- 音楽生成:Suno、Udio
- プログラミング支援:GitHub Copilot、Code Llama
用途ごとに最適化されたモデルを組み合わせることで、さまざまな業務の効率化が可能になります。ここでは、コード生成に活用できる代表的なサービスとして、ChatGPT、Claude、GitHub Copilotの3つを紹介します(2025年8月時点)。
ChatGPT
ChatGPTはOpenAIが開発した生成AIで、自然な対話を通じて問題の解決を図ります。
ChatGPTで使用されている主なモデルは、以下のとおりです。
- GPT-5(最新モデル)
ChatGPTは、膨大なテキストデータを学習しているため、文章の生成からコード生成、翻訳、アイデア出しまで幅広いタスクをこなせます。多様なプログラミング言語に対応しており、コーディングの自動化やバグの修正案の提案、コードの解説による業務効率化が見込めます。
Claude
ClaudeはAnthropicが開発した生成AIで、特に安全性と倫理性を重視しています。Claudeで使用されている主なモデルは、以下のとおりです。
- Claude Opus 4.1
- Claude Sonnet 4
- Claude Haiku 3.5
Claudeは長い文章を一度に処理する能力に優れており、膨大なドキュメントの要約や分析が得意です。ソフトウェア開発の分野では、長文処理能力を活かし、複雑な仕様書や既存のコードベース全体を深く理解した上で、整合性の取れたコードを生成します。
GitHub Copilot
GitHub Copilotは、GitHubとOpenAIが共同開発した、AIコーディング支援サービスです。現在、さまざまなモデルを選択して利用可能で、用途やパフォーマンスに応じた柔軟な対応が可能です。GitHub Copilotで使用されている主なモデルは、以下のとおりです。
【現行モデル】
- GPT‑4.1
- GPT‑4o
【最新モデル(Public Preview)】
- GPT-5
- GPT-5 mini
- OpenAI o3
- OpenAI o4‑mini
GitHub上に存在する膨大なコードデータを学習することで、精度の高いコード生成を実現しています。次に書くべきコードや関数をリアルタイムで提案・自動補完してくれるため、開発スピードの向上が期待できるでしょう。
生成AIを活用する3つのメリット
生成AIへの理解が深まったところで、実際に活用することで得られるメリットを3つ紹介します。
業務の効率化
生成AIは、これまで人間が手作業で行っていた業務を自動化し、大幅な効率化を実現します。例えば、報告書の下書きやメール文面といった定型的な文章作成を生成AIに任せることで、担当者はよりクリエイティブで戦略的な業務に集中できます。プログラムコードの生成やデバッグ補助、データ整理などの作業でも高い効果を発揮します。
コスト削減
業務の効率化は、そのまま人件費や外注費の削減にもつながります。
例えば、
- 生成AIチャットボットによる問い合わせ対応の自動化
- デザインやコンテンツ制作のAI生成による外注費削減
これらの施策により、人的リソースをより付加価値の高い業務へ振り向けることが可能です。具体的な事例は後述の「生成AIにおける業務の活用事例」で詳しく紹介します。
新しいアイデアや視点の獲得
生成AIは、膨大な学習データから、人間では思いつきにくい組み合わせやパターンを見つけ出します。たとえば、新サービスの企画を考える際、生成AIにコンセプト・キーワードを入力するだけで、多様なアイデア案やキャッチコピーを瞬時に生み出すことが可能です。
生成AIの提案をそのまま使用しなくても、企画の幅が広がり、斬新で魅力的なアウトプットにつながるでしょう。
生成AIは、業務効率化やコスト削減、新たな発想の創出など、多くのメリットをもたらします。しかし、その一方で、利用にあたっては無視できない課題やリスクも存在します。次章では、生成AIを導入・運用する際に注意すべきポイントについて詳しく見ていきましょう。
生成AIが抱える課題
生成AIは多くのメリットをもたらす一方で、導入・運用にまつわるコストや計算リソース、さらには環境負荷など、ビジネス利用や社会実装に向けて解決すべき課題を複数抱えています。ここでは特に重要となる「トレーニング・推論にかかるコスト」と「計算リソース負荷と環境への影響」について解説します。
トレーニング・推論にかかるコスト
独自モデルの開発やファインチューニングには高いトレーニングコストがかかり、運用時にも推論コスト(計算リソース費用)が発生して、利用が増えるほど費用が膨らむ点が課題となっています。これらのコストへの対応策としては、導入前にROI(投資対効果)を試算したり、小規模モデルやAPI課金型サービスの利用で初期投資を抑制したり、バッチ処理やキャッシュの活用によって推論コストを最適化するなどの工夫が検討されています。
計算リソース負荷と環境への影響
生成AIの大規模モデルの開発・運用には膨大な計算リソースが必要となり、高性能なハードウェアや多くの電力が求められるため、コストや電力消費量の増加、環境への負荷が大きな課題となっています。複雑な計算処理によって、質問や指示へのレスポンスが遅くなることもあり、自然な対話や迅速な判断が必要な場面で不都合が生じる可能性があります。これらの課題への対策としては、モデルの圧縮や効率化、再生可能エネルギーの活用、高効率なGPU/TPUの採用、利用状況の可視化など、コストと環境負荷の両面で持続可能な運用を目指す工夫が進められています。
生成AI活用のリスクと対策
前章では、生成AIの全体的な課題として「トレーニング・推論にかかるコスト」と「計算リソース負荷と環境への影響」を取り上げました。これらは抽象的な概念にとどまらず、実際の業務利用の現場では、より具体的なリスクとして表面化します。
ここからは、実際にビジネスで生成AIを導入・活用する際に注意すべき4つの主要リスクと、それぞれに対する対策を紹介します。導入前にこれらを把握し、適切な管理体制を整えることが、安全かつ効果的な活用への第一歩となります。
1. 倫理的リスク
生成AIが抱えるリスクのひとつに、倫理的な信頼性の問題があります。学習データに含まれるバイアスや倫理的問題が、そのまま生成結果に反映される可能性があるためです。性別や人種、宗教、文化などに関する差別的・偏見的な表現やコンテンツが生み出される恐れがあることを必ず認識しておきましょう。特に公共や教育現場での利用においては、このリスクは無視できません。
倫理的リスクへの対策
こうしたリスクに対応するためには、生成AIの利用においてバイアスや偏りを事前に検知・抑制する仕組みが求められます。また、倫理的に信頼できるAIを実現するためには、技術面だけでなく、制度や文化といった多角的な観点から、継続的に改善と議論を重ねていくことが重要です。
2. 情報漏洩リスク
生成AIは、入力されたテキストを学習データとして再利用したり、サービス改善のために解析したりします。そのため、プロンプト(生成AIに対して入力する指示文や質問のこと)に機密情報や個人情報を含めると、その内容が学習データとして使われることになり、結果、それらの情報が外部に流出する危険性があります。
また、プロンプトインジェクション攻撃(プロンプトに悪意ある指示を混ぜ、AIをだまして不正に利用する攻撃)によって意図しない内部情報が引き出される可能性も報告されています。
情報漏洩リスクへの対策
機密情報を入力しないルールを社内で明文化し、入力データを学習に利用しない設定を有効に。アクセス権限と操作ログを厳格に管理し、不正利用を監視する体制を整えましょう。
3. 著作権・商標権の侵害リスク
生成AIは学習済みデータを基に出力を生成するため、既存の著作物や商標と酷似した表現が生まれることがあります。文化庁は「AI生成物に著作権が認められるかは利用方法によって判断される」としており、法的解釈は依然として複雑です。
著作権・商標権の侵害リスクへの対策
公開や商用利用の前に専門家またはツールで権利チェックを実施し、引用時は出典を明示。法改正やガイドラインの動向を継続的にモニタリングするとよいでしょう。
4. ハルシネーション(誤情報)リスク
学習データの誤りや偏り、曖昧な指示などが原因で、生成AIは存在しない情報を事実のように出力することがあります。誤情報が拡散されると、信用失墜や社会的混乱につながる恐れがあります。
ハルシネーションへの対策
出力内容を必ず人間がファクトチェックし、検証ツールや多様なデータセットでバイアスを低減。プロンプトは具体的かつ明確に設計して誤認識を防ぐことを意識しましょう。
生成AIを業務に活用している事例
生成AIは、その高度な情報処理能力と創造性を活かし、幅広い業務領域で利用されています。主な活用分野は、大きく以下の3つに分けられます。
- データ分析:大量データからパターンや傾向を抽出し、レポートや可視化を自動生成。
- クリエイティブ制作:文章、画像、動画、音楽、コードなどの多様なコンテンツを自動生成。
- コミュニケーション支援:自然言語での対話、翻訳、顧客対応、情報要約などを支援。
これらの技術は、従来の業務プロセスを効率化するだけでなく、新しいビジネスモデルや価値創造にもつながります。以下では、具体的な活用事例を見ていきます。

文章の要約
生成AIは、長文の文章を短く・分かりやすく要約する能力に優れています。議事録や研究論文、ニュース記事、顧客からの長いメールなどを、自動で要約する際に活躍するでしょう。重要な情報だけを効率的に把握できるようになれば、情報のインプットにかかる時間を短縮できます。
会議音声の文字起こし
生成AIは、会議の音声データを高精度で文字起こしし、さらに議事録を作成することも可能です。結果として、議事録作成業務の負担が軽減され、参加者は議論に集中できるようになります。さらに、文字起こしされたテキストから、重要なポイントや決定事項を自動で抽出する活用方法もあります。
メールの自動返信
受信したメールの内容を理解し、文脈に合った返信文を自動で生成する機能にも、生成AIが活用されています。自動返信機能が利用されている場面は、以下のとおりです。
- カスタマーサポートの自動化
- 営業メールの効率化
- FAQ(よくある質問)の自動生成
生成AIは繰り返し発生するコミュニケーション業務を自動化し、効率化に貢献しています。加えて、専門的なデータを学習すれば、法律・医療といった分野での質問対応も実現可能です。
多言語対応・翻訳
生成AIは、多言語対応と翻訳の分野で大きな力を発揮します。単語やフレーズを直訳するだけでなく、文脈を深く理解した上で、より自然な翻訳文を生成できるためです。生成AIを活用することで、国際的なビジネス文書の作成や、海外顧客とのコミュニケーションがスムーズになるでしょう。そのほか、Webサイトの多言語化やグローバルな会議での通訳など、多様なシーンでの活用が期待されています。
リサーチ・分析
人間が手作業で行うよりも生成AIを使うほうが、短時間で広範なリサーチ・分析ができます。たとえば、特定の業界の市場トレンドや競合製品の機能、マーケティング戦略、顧客の評判などを自動でリサーチし、レポート形式で要約することが可能です。市場の変化に迅速に対応し、効果的なビジネス戦略を立てる上で、生成AIは強力なリサーチアシスタントとなり得ます。
コピーのアイデア生成
マーケティングや広告の分野では、キャッチコピーや広告文のアイデア生成にAIが利用されています。クリエイターがゼロからアイデアを絞り出す手間を軽減できる点がメリットです。生成されたアイデアをもとにして人間が洗練させれば、より効果的な広告表現を生み出せるでしょう。
画像・動画作成
既述のとおり、生成AIは、画像や動画も作ることができます。テキストで具体的なイメージを指示すれば、AIは要望に合った画像を生成したり、既存の画像を加工したりできます。デザインの専門知識がない人でも簡単に素材を用意でき、コンテンツ作成のスピードアップとコスト削減が図れます。
プログラムコードの生成・バグ修正
ソフトウェア開発の現場では、生成AIによるプログラムコードの自動生成やバグ修正に役立てられています。生成AIの導入で、プログラマーの人為的なミスを防ぎつつ、コード全体の品質が向上するでしょう。リアルタイムでの処理に優れる生成AIを取り入れた場合、さらにコーディング作業にかかる時間を短縮できます。
ここまで、生成AIが活躍できる具体的な事例を紹介しました。しかし、万能に見える生成AIにも、現時点では苦手とする分野や限界があります。
その特性を理解しておくことは、業務における適切な役割分担や、AIの過信を避けるうえで重要です。
生成AIに向いていないこと
生成AIに得意な領域がある一方で、現状では人間でなければ難しいタスクも存在します。主な例は以下のとおりです。
- 主観的なクリエイティブ作業
唯一無二の芸術作品や、作り手の個性や経験に基づく創作活動は、AIよりも人間が優れています。 - 合理的ではない思考、感情の理解
論理では説明できない複雑な感情や、直感・ひらめきに基づく判断はAIが不得意です。 - 学習データを超えた生成
AIは学習データに含まれる情報のパターンを利用して生成します。未知の概念や、全く新しい理論の創造は困難です。 - 倫理的・道徳的な判断
社会的価値観や文化的背景を踏まえた判断は、単なるデータ処理だけでは対応できません。
AIが生成するコンテンツは、あくまで学習データのパターンにもとづいた結果といえます。したがって、唯一無二の芸術作品の創作や、合理的ではない複雑な感情を表現するような作業は、引き続き人間の役割が大きいです。
生成AIを社内活用するならOSSも検討しよう
OSS(オープンソースソフトウェア)は、ソースコードが公開され、ライセンス条件の範囲内で第三者が基本的に無料で使用、複製、改変、再配布などを行えるソフトウェアです。
企業で生成AIを導入する際、OSSツールを活用することは、セキュリティ確保やコスト削減の面で有効な選択肢となります。
生成AIのOSS・ツール
生成AI分野では、多くの優れたOSSツールが公開されており、用途や状況に応じて使い分けることが可能です。OSSは大きく以下の5つの領域に整理できます。
- OSS LLM(モデルそのもの):大規模言語モデル自体。学習済みモデルやその重みが公開され、利用可能なもの。ライセンス形態はさまざまで、完全OSSのものから利用制約付きのものまで存在します。
- モデル学習OSS(AIを「育てる」段階で利用):自分でモデルを学習したり改良したりするためのツール。大量のデータと計算資源が必要です。
- 推論OSS(学習済みモデルを「使う」段階で利用):既に学習されたモデルを利用してテキスト生成や解析を行うためのツール。API経由やローカル環境で利用できます。
- アプリ開発OSS(生成AIアプリを「作る」ために利用):複数のモデルや機能を組み合わせて、サービスやアプリを開発するための仕組み。RAGやエージェント構築にも利用されます。
- 周辺/インフラOSS(AIの活用を支える基盤):大規模化・実運用に備えて必要となる基盤。ベクトルデータベース、データ前処理、クローラ、評価・監視ツールなどが含まれます。
領域ごとに、代表的なOSSを以下の表に整理しました。
| OSSの種類 | 代表的なOSSツール |
|---|---|
| OSS LLM (モデルそのもの) |
|
| モデル学習OSS |
|
| 推論OSS |
|
| アプリ開発OSS |
|
| 周辺/インフラOSS |
|
OSSのAI導入のメリット
OSSの生成AIを導入する主なメリットは、以下の2点です。
- 情報漏えいリスクを低減できる
- 導入・運用コストを抑えられる可能性がある
OSSの生成AIを自社サーバで運用する場合、機密情報や個人情報を外部のAIサービスに送信する必要がありません。これにより、意図しない情報漏えいのリスクを軽減し、セキュリティを自社で管理することができます。
また、OSSの生成AIはライセンス費用がかからないため、API課金型サービスやSaaS型の生成AIと比較して、自社で十分な運用体制やインフラを持っている場合には、導入・運用コストを抑えられる場合があります。特に、大量の処理や長期間の運用では、従量課金制のサービスよりもコスト面で有利になるケースがありますが、初期のセットアップや自社での運用・保守が必要な点は留意が必要です。
OSSの生成AIを導入した事例
OSSのAIを導入して業務を改善した事例を、以下にまとめました。生成AIができる業務の幅は大変広いです。ぜひご自身の会社にはどんな形で導入できるのかを思い描く参考にしてみてください。
| 導入企業 | 事例内容 |
|---|---|
| 野村総合研究所(NRI) |
Llama 3.1 Swallow 8B(オープンウェイトLLM(※))を基盤に、業界・タスク特化型LLMの構築手法を独自に開発。保険業界のコンプライアンス判定でGPT-4oを上回る精度を実証しました。 |
| ゴールドマン・サックス |
「Llama 3」を導入し、社内文書のレビュー作業を自動化して、業務効率を高めた。 |
| レクサス |
「Stable Diffusion XL」を活用し、展示会で来場者参加型ブースを展開。生成画像のSNS投稿率を向上させた。 |
| BBC Sounds |
「Whisper」を用いて月2.7万時間の音声番組に字幕を付け、聴覚障がい者向けアクセシビリティを強化した。 |
参考URL:野村総合研究所、業界・タスク特化型LLMの構築手法を独自に開発
参考URL:Reuters|Meta says its Llama AI models being used by banks, tech companies
参考URL:Lexus USA Newsroom|2023 New York International Auto Show Guests Use Artificial Intelligence to Create their Picture-Perfect Lexus
参考URL:Raconteur|How BBC Sounds is using GenAI to boost accessibility in audio
(※)「オープンウェイト」とは、モデルの重みを公開し利用可能にした形態を指します。ただし、MITやApacheのような完全なオープンソースソフトウェアとは異なり、利用条件や制限(例:利用規模の制限)が設けられています。
OSSのAIを導入する際の注意点
OSSのAIを導入する際に意識すべきポイントは、大きく次の2つです。
- 使用目的や自社の既存の開発環境に合ったAIを選定する
- ライセンス条件を正しく確認する
OSSのAIは、それぞれ得意分野や必要な技術環境が異なります。自社の目的や既存のシステムに合わないAIを選んでしまうと、開発がスムーズに進みにくいため、慎重な選定が重要です。また、OSSは基本的に無料で利用できますが、「OSSライセンス」と呼ばれる利用許諾条件を遵守しなければいけません。ソースコードの公開義務が生じるライセンスもあるため、導入前に利用許諾条件を正確に理解する必要があります。
OSSライセンスについては、こちらをご参照ください。
OSSライセンスとは?種類や違反事例、確認方法を解説
さらに、技術的な問題や法的なリスクへの対応としては、AIに詳しい専門家や弁護士に相談することが有用です。
生成AIの今後
最後に生成AIの今後の展望について、注目するべきトレンドを3つ紹介します。
マルチモーダルモデルの発展
生成AIにおける今後の大きなトレンドとして「マルチモーダルモデル」の発展が挙げられます。現在、多くの生成AIはテキスト・画像・コードといった、単一の種類のデータに特化しています。対して、マルチモーダルモデルは、異なる種類のデータを統合して処理するモデルです。たとえば、テキストで指示するだけで画像を生成し、さらに画像に関する説明音声を自動で生成する、などの活用方法が考えられます。今後、マルチモーダルモデルの発展により、分野別に異なるモデルを使い分ける意識は少なくなるかもしれません。ただし、医療や法律といった高い専門性が求められる分野では、引き続き特定のタスクに最適化されたモデルが重要視される可能性もあります。
軽量化・省電力化モデルの普及
高性能GPUや大規模クラウド環境に依存せず、一般的なPCやスマートフォンでも生成AIを動かせるようにする動きが加速しています。これにより、企業だけでなく個人や小規模チームでも高度なAI活用が可能になります。
セキュリティ・ガバナンスの強化
情報漏えい対策や生成物の信頼性担保を目的に、モデルの利用監査や生成結果の検証ツールの導入が進んでいます。特に企業や公共機関では、AI活用と同時にガバナンス体制の構築が求められるようになるでしょう。
まとめ
生成AIは従来のAIと異なり、学習データから新しい文章や画像、コードなどを創り出す(生成する)ことに特化しています。生成AIの特性を活かせば、文章の要約や作成、コードの生成といった幅広い業務の効率化が見込めるでしょう。
多大なメリットをもたらす反面、生成AIには情報漏洩や著作権侵害、誤情報の生成といったリスクも存在します。リスクを軽減するには、機密情報の入力制限やチェック体制の整備、社内マニュアル作成のような組織的な運用ルールの構築が不可欠です。
生成AIは、適切な理解と運用ルールのもとでこそ、その真価を発揮します。利便性と安全性のバランスを取りながら、戦略的に活用していくことが今後ますます重要になるでしょう。
OpenStandiaサービス
OpenStandiaは、野村総合研究所(NRI)が提供するオープンソースソフトウェア(OSS)利用の課題を解決する安心のワンストップサービスです。
OSS利用の課題を解決し、企業にもたらすOSSのメリットを感じていただくためのさまざまなサポート&サービスメニューをご用意しています。
関連ブログ



関連OSS
-

TensorFlow
テンソルフロー。Googleが開発を行っている機械学習/ディープラーニング/多層ニューラルネットワークライブラリです。
-

PyTorch
パイトーチ。オープンソースのPythonの機械学習フレームワークです。
-
n8n
n8nは、ネットワーク上の様々なサービスを接続し、ビジネスまたは個人の作業をノーコードまたはローコードで自動化するツールです。
-

H2O(機械学習プラットフォーム)
エイチツーオーは、線形スケーラビリティーで拡張可能な分散型インメモリー機械学習プラットフォームです。